Cloudflare, Unikernels & Bare Metal: Life of a Prisma Postgres Query

Prisma Postgres is the most innovative PostgreSQL database on the market. In this article, we dive deep into its technology stack, which enables lightning-fast queries, global caching, connection pooling, and more.
Recap: What is Prisma Postgres?
In case you haven't heard: Prisma Postgres is the first database built on unikernels. Here's a quick 100-second summary if you missed it:
Built on next-generation infrastructure
Prisma Postgres is not just another AWS wrapper! Its architecture has been carefully designed from first principles and builds on next-generation infrastructure like unikernels, Unikraft Cloud and Cloudflare Workers.
The combination of these technologies provides unique benefits and a powerful feature set.
No cold starts, global caching, connection pooling & more
Here's what developers get when using Prisma Postgres as their serverless database:
- Zero cold starts: Instant access to your database without delays.
- Generous free tier: 100k operations, 1GiB storage per month & 10 databases.
- Global caching layer: Query responses are easily cached at the edge.
- Built-in connection pool: Scale your app without worrying about TCP connections.
- Performance tips: AI-powered recommendations for speeding up your queries.
- Simple pay-as-you-go pricing: Predictable costs based on operations & storage.
Life of a Prisma Postgres query
With our short recap out of the way, let's dive into the tech stack Prisma Postgres uses to enable these benefits. Spoiler: Here's the full overview of all components involved in the lifecycle of a Prisma Postgres query:
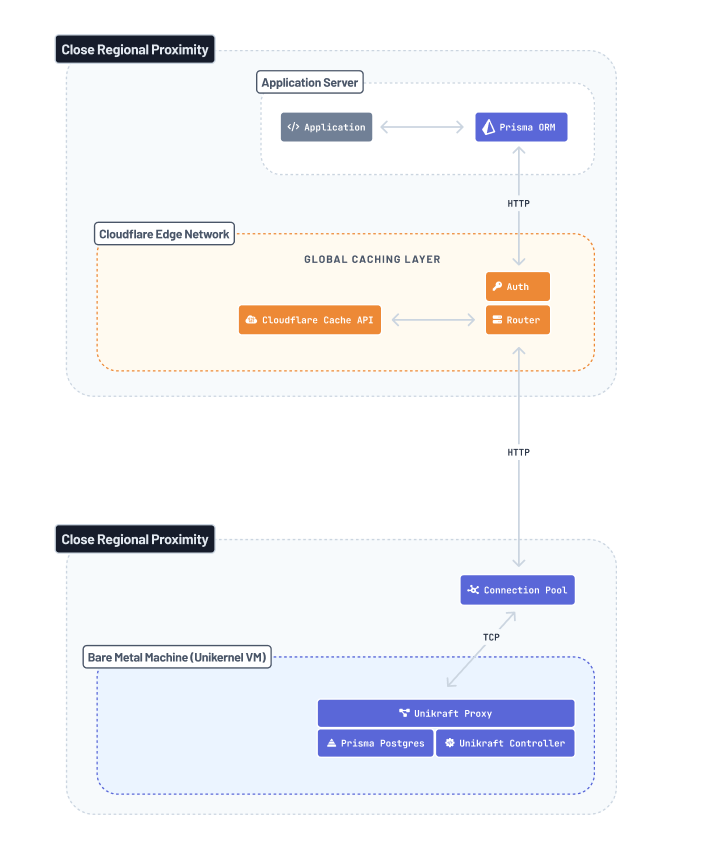
In the next sections, we'll take a closer look at each stage and explain what's going on under the covers.
Stage 1: It all starts with Prisma ORM
Prisma ORM is where the journey of a Prisma Postgres query naturally starts.
No query engine needed on the application server with Prisma Postgres
If you've used Prisma ORM in the past, you may be aware that it uses a Query Engine that's implemented in Rust and which runs as a binary on your application server.
Note that while we're still talking about the Query Engine being written in Rust in this context, it is currently being rewritten in TypeScript. Learn more here.
The core responsibilities of the Query Engine are:
- Generating an efficient SQL query based on the high-level ORM query (written in JS/TS)
- Managing the database connection pool
The neat thing about using Prisma ORM with Prisma Postgres though is that you don't need the Query Engine running on your application server. Instead, you'll use a super lightweight version of Prisma ORM without the Query Engine. The heavy-lifting of generating SQL queries and managing TCP connections is pushed down further in the stack into the connection pool that sits on top of Prisma Postgres.
This approach of hosting the connection pool on the Prisma Postgres infrastructure has major benefits: Freeing application developers from managing the connection pool lets them focus on their data needs and queries. It is also especially useful in short-lived environments, like serverless and edge functions, where re-creating the connection pool again and again causes a major performance overhead.
Defining a Prisma ORM query with a cache strategy
Let's use the following Prisma ORM query for the purpose of this article:
const users = await prisma.post.findMany({
where: { published: true },
cacheStrategy: {
ttl: 60,
swr: 30,
}
})This query fetches all published posts from the database and additionally specifies two parameters that will be relevant for the Prisma Postgres cache:
- Time-To-Live (
ttl): Determines how long cached data is considered fresh. When you set a TTL value, Prisma Postgres will serve the cached data for that duration without querying the database. - Stale-While-Revalidate (
swr): Allows Prisma Postgres to serve stale cached data while fetching fresh data in the background. When you set an SWR value, Prisma Postgres will continue to serve the cached data for that duration, even if it's past the TTL, while simultaneously updating the cache with new data from the database.
In this example, the data will be considered fresh for 30 seconds (TTL). After that, for the next 60 seconds (SWR), Prisma Postgres's cache will serve the stale data while fetching fresh data in the background.
Prisma Postgres serves cached data from an edge location close to your application. If you deploy your app to multiple locations, this global cache can dramatically improve the performance of your app!
Executing the query via HTTP
So, when the query above is executed in an application, what happens next? Because the Query Engine has been pushed down the stack, all that happens at this stage is an HTTP request to the first auth and routing layers of Prisma Postgres' infrastructure. This HTTP request carries a lightweight, JSON-based representation of the query. Here is what it looks like:
{
"modelName": "Post",
"action": "findMany",
"query": {
"arguments": {
"where": {
"published": true
}
},
"selection": {
"$scalars": true
}
}
}Note that the selection argument specifies the fields that should be fetched from the database. Since we didn't use a select or include option on our query, its value simply is "$scalars": true which means that all scalar fields of the target model will be return from the database.
The next step for the request to be evaluated by Prisma Postgres' authentication and cache layers.
Stage 2: Authenticating the request
Before hitting the cache to check if the query result can be served from there, the query needs to be authenticated. A Prisma Postgres URL always contains an apiKey argument that encodes the user credentials:
prisma+postgres://accelerate.prisma-data.net/?api_key=ey...The auth layer is implemented using Cloudflare Workers, and therefore in close physical proximity to the origin of the query. It uses the apiKey value to identify the user, validate the access permissions and route the request to the next stage.
Stage 3: To cache or not to cache
After authentication, the HTTP request is going to hit the next layer of the Prisma Postgres infrastructure which is implemented via Cloudflare Workers as well:
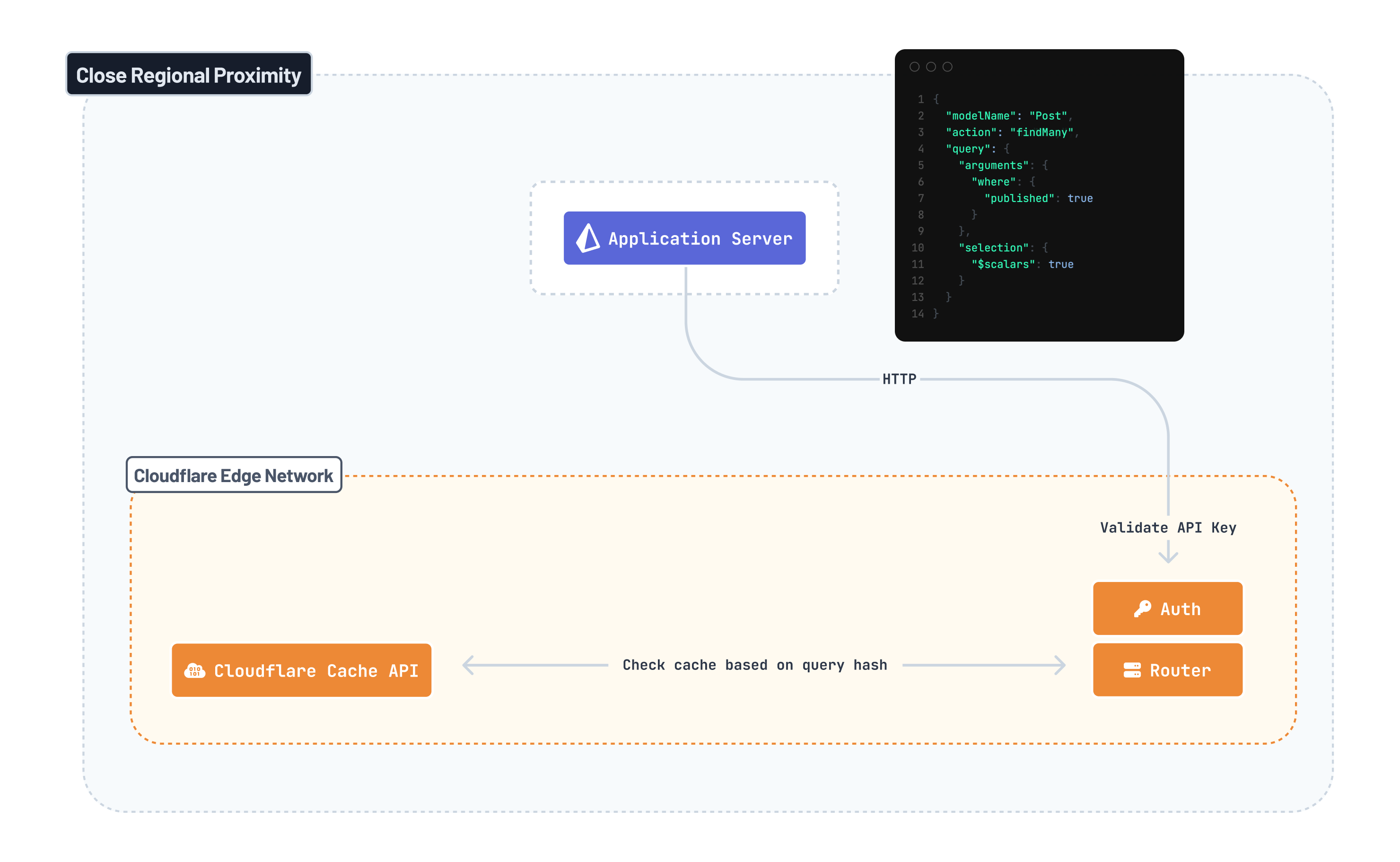
The main purpose of this routing layer is to determine whether the Prisma Postgres cache needs to be activated:
- If the query has
swrand/orttloptions set, the query will enter the path to the Prisma Postgres cache. - If the query doesn't have either of these caching options, it will directly move to the next stage.
So, let's investigate the path through Prisma Postgres' caching layer.
Being built on top of Cloudflare Workers, the Prisma Postgres cache takes advantage of the official Cloudflare Cache API.
As a cache key, it uses a hash that's computed based on the entire Prisma ORM query (including values for the query parameters, such as published: true in the case above). This approach errs on the side of cache misses and only returns data from the cache if there's a 100% certainty that this exact query was sent to the database and that its result was cached before.
You can see the statistics of your caching behavior in the Prisma Postgres dashboard:
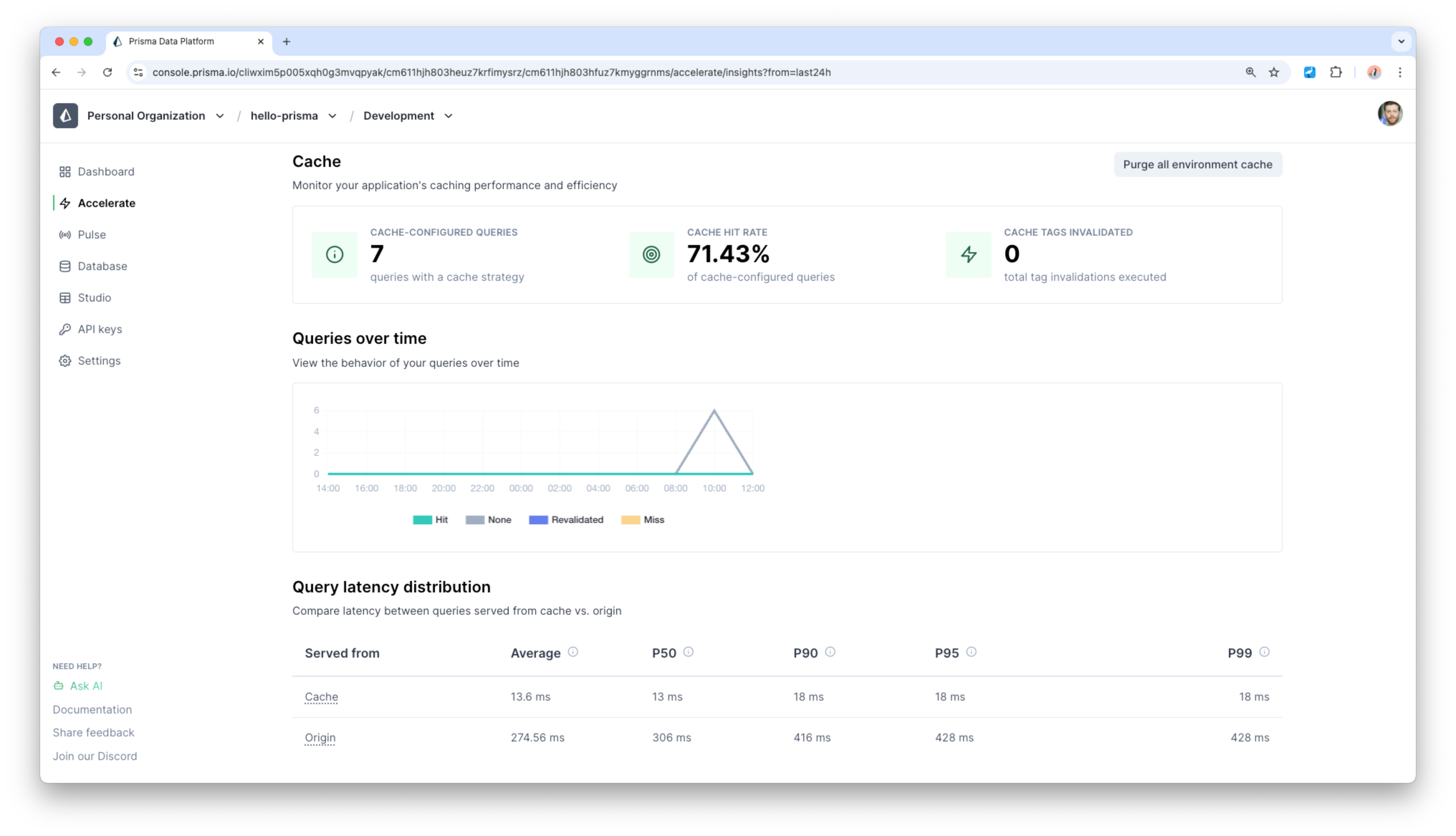
Let's now assume our query from before continues to travel down the Prisma Postgres stack and is not served by the cache. What happens next?
Stage 4: Hitting the connection pool
If the query result has not been cached, the HTTP request from before will be forwarded to the next stop: Prisma Postgres' connection pool (which is deployed on VMs running in close physical proximity to the database instances).
Learn more about why connection pooling is important in our recent article: Saving Black Friday With Connection Pooling
Note that this is actually the first (and only) time the request may travel a longer distance because it now leaves the regional bounds of a Cloudflare region.
These VMs host the Query Engine that was moved out of the application server (as explained in stage 1). So, at this stage, Prisma Postgres' connection pool not only finds an idle connection to actually execute the query, it also generates the SQL statement that will be sent to Prisma Postgres. This is now done via a good old TCP connection to the database.
Stage 5: Entering the unikernel database
Prisma Postgres is based on unikernels (think: "hyper-specialized operating systems") running as ultra-lightweight microVMs on our own bare metal servers.
Check out the Early Access announcement to learn about the details of that architecture, our collaboration with Unikraft, and the millisecond cloud stack that enables the performance benefits of Prisma Postgres.
Here's an overview of the Unikraft Cloud's core components that enables the lightning-fast startup times of Prisma Postgres instances:

And this is how these components work together:
- Custom controller and proxy: A custom platform controller that provides best-in-class, reactive, millisecond semantics and scalability. To make network processing fast, Unikraft Cloud couples this controller with a custom proxy which takes care of load-balancing and is able to very quickly react to incoming requests. This proxy is where Prisma Postgres' TCP connections to the connection pool are being managed.
- Fast Virtual Machine Monitor (VMM) based on Firecracker and unikernels: Unikraft Cloud's unikernels use lean images containing only Prisma Postgres — nothing more. Paired with a modified version of Firecracker VMM, these Prisma Postgres images start lightning fast.
- Snapshotting: Unikraft Cloud takes memory snapshots of Prisma Postgres instances before scaling them to zero. When waking them up, they resume from the snapshot, which means that VMs are already "warm" and even include already active TCP connections!
Thanks to this highly efficient stack, a database instance incurs costs only when you actually use it. This enables us to provide a generous free tier where you can spin up as many free Prisma Postgres instances as you like (as opposed to other providers where you typically need to pay a fixed, monthly cost if you create more than one database instance).
Back to our query: After the initial JSON representation of the query has been transformed into an efficient SQL statement, the query finally reaches the database layer via TCP. The PostgreSQL instances are deployed using Unikraft's millisecond cloud stack on our own bare metal servers in close proximity to the connection pool.
The first stop here is the Unikraft proxy which is responsible for maintaining the TCP connections to the connection pool.
The proxy now talks to the Unikraft controller which is responsible for managing the actual Prisma Postgres instances. At this point, there are two possible states:
- either the target Prisma Postgres instance is already up-and-running; in this case the proxy will go ahead and continue to forward the query directly to it.
- or the Prisma Postgres instance is currently "paused"; in this case the proxy will reach out to the Unikraft controller which is responsible for identifying the target Prisma Postgres instance, "waking it" up and informing the proxy about the current instance status.
Don't get confused by the "pause" and "wake up" terminology here. Thanks to the ultra-fast VM snapshotting (which happens in memory) and the lightweight of the unikernels, each instance can be woken up again in a matter of single-digit milliseconds (which is the secret to why Prisma Postgres instances don't suffer from cold starts).
What's next for the Prisma Postgres architecture?
While we've seen a lot of excitement about the current technology stack and the benefits it provides to developers already, we are not going to stop here!
There are a number of additional optimizations that we see possible in future iterations of Prisma Postgres, most notably: We are going to move the connection pool onto the same machines that are running the Prisma Postgres instances:
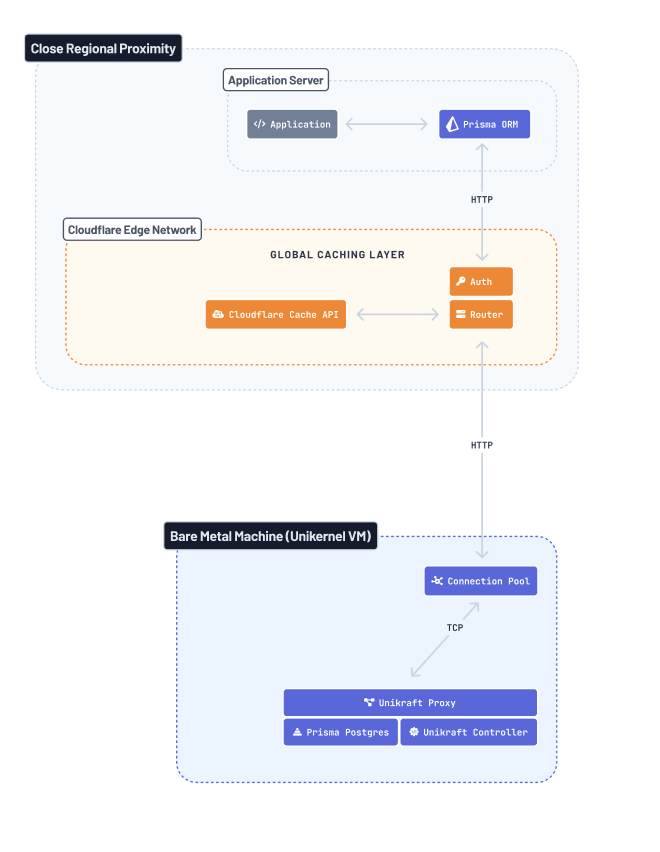
The TCP connection is the most expensive part in the entire stack, due to the three-way handshake that needs to be done every time a connection is established. By reducing this TCP connection to a merely local one happening between two processes on the same machine, the latency caused by the physical distance between the connection pool and database instance would become entirely negligible.
This is the core advantage of Prisma Postgres compared to other providers that are based on AWS (or another cloud provider's) infrastructure: When using a cloud provider, there's no guarantee that the connection pool and database instance are running on the same host but there's always going to be a network hop.
Conclusion
In this article, we looked under the covers of Prisma Postgres and the next-generation technology stack it's built on.
If you are already using Prisma ORM, give Prisma Postgres a try by importing the data from your existing database in . Otherwise, try out Prisma Postgres from scratch by running this command in your terminal:
npx prisma@latest init --db