Database vs Application: Demystifying JOIN Strategies

Joining data from multiple tables is a complicated topic. There are two main strategies: database-level and application-level joins. Prisma ORM offers both options. In this article you’ll learn the tradeoffs between the two so you can pick the best strategy for your use case.
Introduction
Why did Prisma ORM initially only have application-level joins?
Prisma ORM initially only offered an application-level join strategy. There were several reasons for this choice:
- Ability to use the same join strategy across database engines, ensuring portability.
- Increased scalability of the overall system by moving expensive operations to the application layer (which is easier and cheaper to scale than the database).
- Cloud-native and serverless use cases where co-location of application and database in the same cloud region is the norm and the overhead of additional round trips to the database becomes negligible.
- High-performance use cases with millions of rows and deeply nested queries using additional features like filters and pagination.
- Simplicity in query debugging because each query only targets a single table (no need to understand and debug complex query plans).
- Predictable performance by limiting the database responsibility to straightforward operations and preventing the significant variations in query performance depending on the database's query planner and runtime optimizations.
In February 2024, Prisma ORM added smart DB-level joins as an alternative strategy using modern database features like LATERAL joins and JSON aggregation. This approach is favorable when the application and DB servers are far apart from each other and the cost of the additional network round trips contributes substantially to the overall latency of a query.
Ultimately, each of these approaches comes with its own set of tradeoffs, which we'll illuminate in the remainder of this article to help you pick the best strategy for your relation queries.
Nested objects vs foreign key relations
Before diving into the complexities of joins, let's quickly zoom out and understand what the topic of "joining data" is all about.
As a developer, you're probably used to working with nested objects, which look similar to this:
{
post: {
title: "What are database JOINs",
author: {
name: "Ada Lovelace",
email: "lovelace@prisma.io",
profile: {
bio: "Passionate about computer architecture"
}
}
}
}In this example, the "object hierarchy" is as follows: post → author → profile.
This kind of nested structure is how data is represented in most programming languages that have the concept of an object.
However, if you've worked with a SQL database before, you're probably aware that related data is represented differently there, namely in a flat (or normalized) way. With that approach, relations between entities are represented via foreign keys that specify references across tables.
Here's a visual representation of the two approaches:
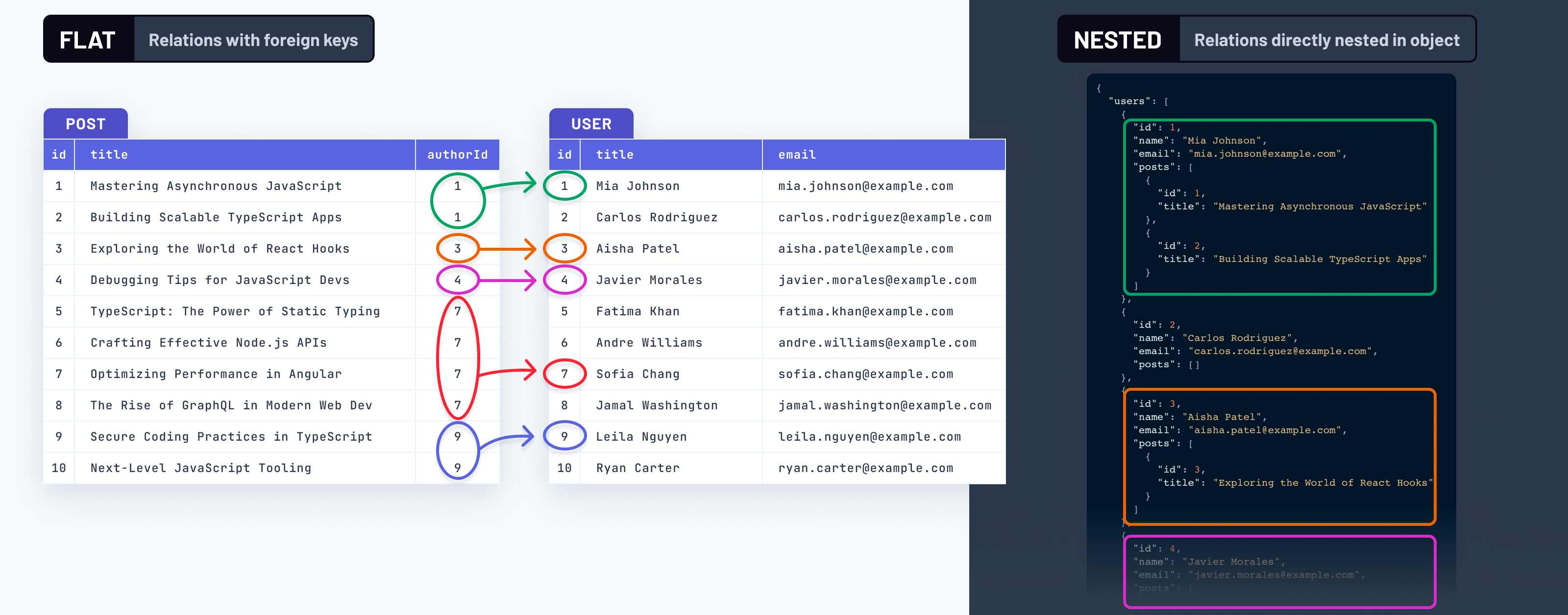
This is a huge difference, not only in the way data is physically laid out on disk and in memory, but also when it comes to the mental model and to reasoning about the data.
What does "joining" data mean?
The process of joining data refers to getting the data from the flat layout in a SQL database into a nested structure that an application developer can use in their application.
This can happen in one of two places:
- In the database: A single SQL query is sent to the database. The query uses the
JOINkeyword (or potentially a correlated subquery) to let the database perform the join across multiple tables and returns the nested structures. There are multiple ways of doing this join that we'll look at in the next section. - In the application: Multiple queries are sent to the database. Each query only accesses a single table and the query results are then joined in the application layer.
Database-level joins have their benefits, but also some drawbacks if they're becoming too complex. Hence, either approach may be more suited for a particular use case than the other, depending on factors like the schema, dataset, and query complexity. Read on to learn about the details!
Three JOIN strategies: Naive, smart & application-level JOINs
At a high-level there are three different join strategies that can be applied, "naive" and "smart" JOINs on the DB-level, as well as "application-level" joins. Let's examine these one by one by use of the following schema:
model comments {
id Int @id @default(autoincrement())
body String
post_id Int?
posts posts? @relation(fields: [post_id], references: [id], onDelete: Cascade)
@@index([post_id], map: "idx_comments_post_id")
}
model posts {
id Int @id @default(autoincrement())
title String
author_id Int?
comments comments[]
users users? @relation(fields: [author_id], references: [id])
@@index([author_id], map: "idx_posts_author_id")
}
model users {
id Int @id @default(autoincrement())
name String?
posts posts[]
}CREATE TABLE users (
id SERIAL NOT NULL,
name TEXT,
CONSTRAINT users_pkey PRIMARY KEY (id)
);
CREATE TABLE posts (
id SERIAL NOT NULL,
title TEXT NOT NULL,
author_id INTEGER,
CONSTRAINT posts_pkey PRIMARY KEY (id),
CONSTRAINT posts_author_id_fkey FOREIGN KEY (author_id) REFERENCES users(id) ON DELETE SET NULL ON UPDATE CASCADE
);
CREATE TABLE comments (
id SERIAL NOT NULL,
body TEXT NOT NULL,
post_id INTEGER,
CONSTRAINT comments_pkey PRIMARY KEY (id),
CONSTRAINT comments_post_id_fkey FOREIGN KEY (post_id) REFERENCES posts(id) ON DELETE CASCADE ON UPDATE CASCADE
);
CREATE INDEX idx_posts_author_id ON posts(author_id);
CREATE INDEX idx_comments_post_id ON comments(post_id)Naive DB-level JOINs lead to redundant data
A naive DB-level JOIN refers to JOIN operations that don't take any additional measure for optimizations. These kinds of JOINs are often bad for performance for several reasons, let's explore!
For example, here's a simple LEFT JOIN operation that a developer may naively write to join the data from the users and post tables:
SELECT
users.id AS user_id,
users.name AS user_name,
posts.id AS post_id,
posts.title AS post_title
FROM
users
LEFT JOIN
posts ON users.id = posts.author_id
ORDER BY
users.id, posts.id;The results returned by the database may look similar to this:
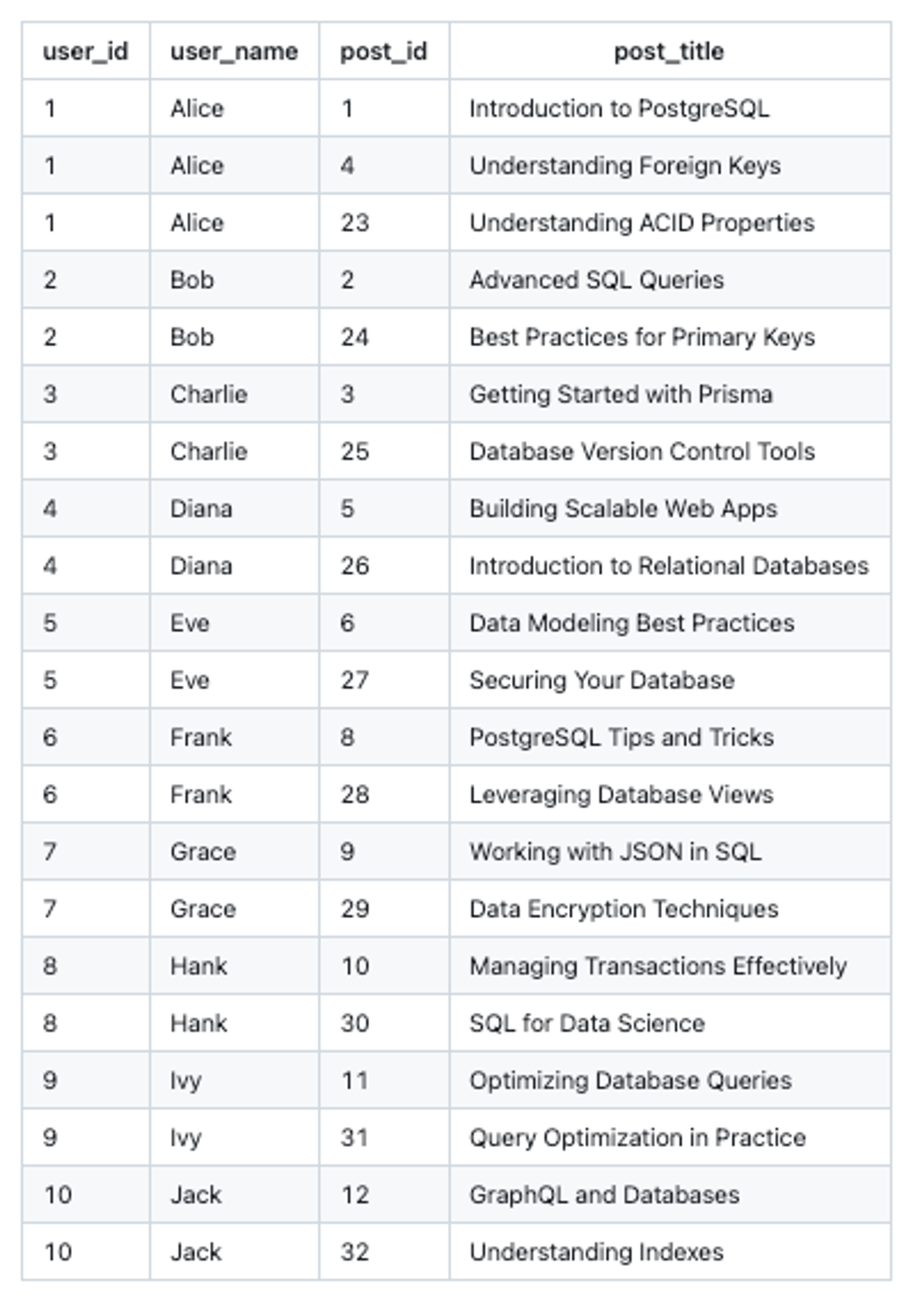
Do you notice something? There's a lot of repetition in the data on the user_name column.
Now, let's add the comments to the query:
SELECT
users.id AS user_id,
users.name AS user_name,
posts.id AS post_id,
posts.title AS post_title,
comments.id AS comment_id,
comments.body AS comment_body
FROM
users
LEFT JOIN
posts ON users.id = posts.author_id
LEFT JOIN
comments ON posts.id = comments.post_id
ORDER BY
users.id, posts.id, comments.idNow that's even worse! Not only user_name repeats, but post_title does so as well:
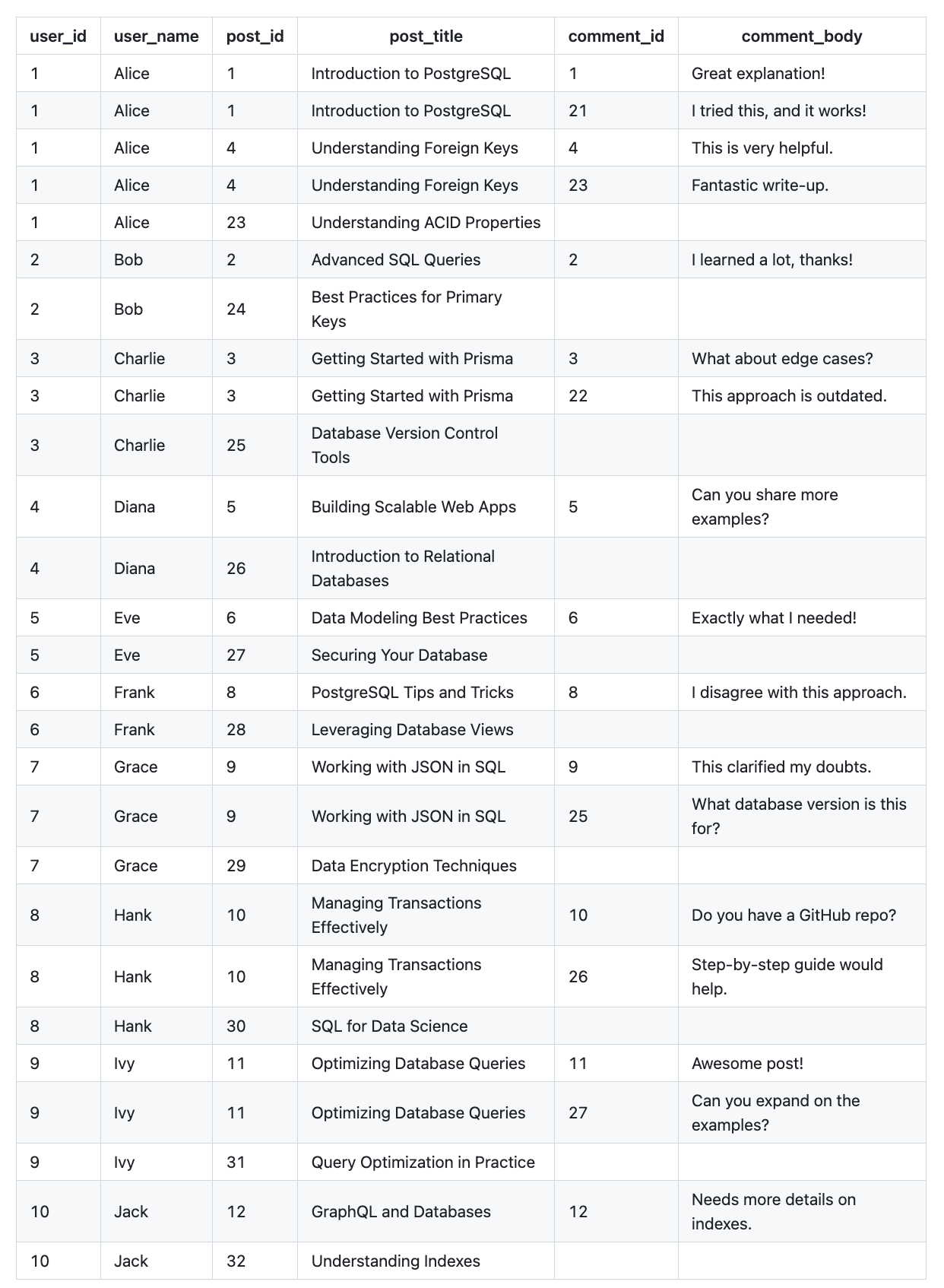
The redundancy of the data has several negative implications:
- Increased amount of (unnecessary) data that's sent over the wire, costing network bandwidth and increasing overall query latency.
- The application layer needs to do additional work to arrive at the desired nested objects:
- deduplicate the redundant data
- re-construct the relationships between the data records
Additionally, this kind of operation incurs a high CPU cost on the database, because it will query all three tables and perform its own in-memory mapping to join the data into one result set.
The above is still a relatively simple example. Imagine you do this with even more JOINs and more nesting. After a certain level, the database will give up on optimizing the query plan and just execute table scans for every table, then stitch the data together in memory using its own CPU. This gets expensive fast!
Database CPU and memory are significantly more complex (and costly) to scale than application-level CPU and memory. So, one way how to improve the situation is by using the CPU of the application server to do the work of joining the data, which leads us to the next approach: "application-level joins".
Application-level joins are simple and efficient but have a network cost
Another alternative of doing these naive, DB-level joins is to join the data in the application layer. With that scenario, the developer formulates three different queries that are sent to the database individually. Once the database has returned the results for the queries, the developer can apply their own business logic to join the data themselves.
In TypeScript, an example for this could look as follows (using a plain Postgres driver like node-postgres):
// Fetch data individually
const usersResult = await client.query('SELECT * FROM users');
const postsResult = await client.query('SELECT * FROM posts');
const commentsResult = await client.query('SELECT * FROM comments');
// Convert results to objects for easier processing
const users = usersResult.rows;
const posts = postsResult.rows;
const comments = commentsResult.rows;
// Create maps for efficient lookup
const postsByUserId: Record<number, any[]> = {};
posts.forEach((post) => {
if (!postsByUserId[post.author_id]) {
postsByUserId[post.author_id] = [];
}
postsByUserId[post.author_id].push(post);
});
const commentsByPostId: Record<number, any[]> = {};
comments.forEach((comment) => {
if (!commentsByPostId[comment.post_id]) {
commentsByPostId[comment.post_id] = [];
}
commentsByPostId[comment.post_id].push(comment);
});
// Join data in the application layer
const joinedData = users.map((user) => {
const userPosts = postsByUserId[user.id] || [];
const postsWithComments = userPosts.map((post) => ({
...post,
comments: commentsByPostId[post.id] || [],
}));
return {
...user,
posts: postsWithComments,
};
});There are several benefits to this approach:
- The database will generate a highly optimal execution plan for each of these queries and do virtually no CPU work since it's simply returning data from a single table.
- The data sent over the wire is optimized for the data needs of the application (and doesn't suffer from the same redundancy problems as the naive DB-level join strategy).
- Since the bulk of the mapping and joining work is now done in the application itself, the database server has more resources to serve more complex queries.
By shifting CPU cost from the database to the application layer, this approach enhances the horizontal scalability of the entire system.
In the O' Reilly book High Performance MySQL, this technique of application-level joins is called join decomposition: "Many high-performance web sites use join decomposition. You can decompose a join by running multiple single-table queries instead of a multitable join, and then performing the join in the application."
A major drawback, however, is that it requires multiple round trips to the database. In case the application server and database are located far apart from each other, this is a considerable factor that has severe performance implications and likely makes this strategy unviable. If database and application are hosted in the same region, the network overhead most often is negligible though and this approach may prove more performant overall.
Smart DB-level joins solve the redundancy problem
Naive DB-level joins are almost never the best way to retrieve related data from your database, but does that mean your database should never be responsible for joining data? Certainly not!
Database engines have become very powerful in the past years and constantly improved the ways how they optimize queries. In order to enable a database to generate the most optimal query plan, the most important thing is that it can understand the intent of a query.
There are two different factors to this:
- reducing redundancy using techniques like JSON aggregation
- using modern database features like
LATERALjoins in PostgreSQL (or correlated subqueries in MySQL) that contain query complexity
Using the same schema example from above, a good way to represent this is:
SELECT
u.id AS user_id,
u.name AS user_name,
COALESCE(
json_agg(
json_build_object(
'post_id', p.id,
'post_title', p.title,
'comments', (
SELECT COALESCE(
json_agg(
json_build_object(
'comment_id', c.id,
'comment_body', c.body
)
), '[]'
)
FROM comments c
WHERE c.post_id = p.id
)
)
) FILTER (WHERE p.id IS NOT NULL), '[]'
) AS posts
FROM
users u
LEFT JOIN LATERAL (
SELECT
p.id,
p.title
FROM
posts p
WHERE
p.author_id = u.id
) p ON true
GROUP BY
u.id;Such a query produces the following results:
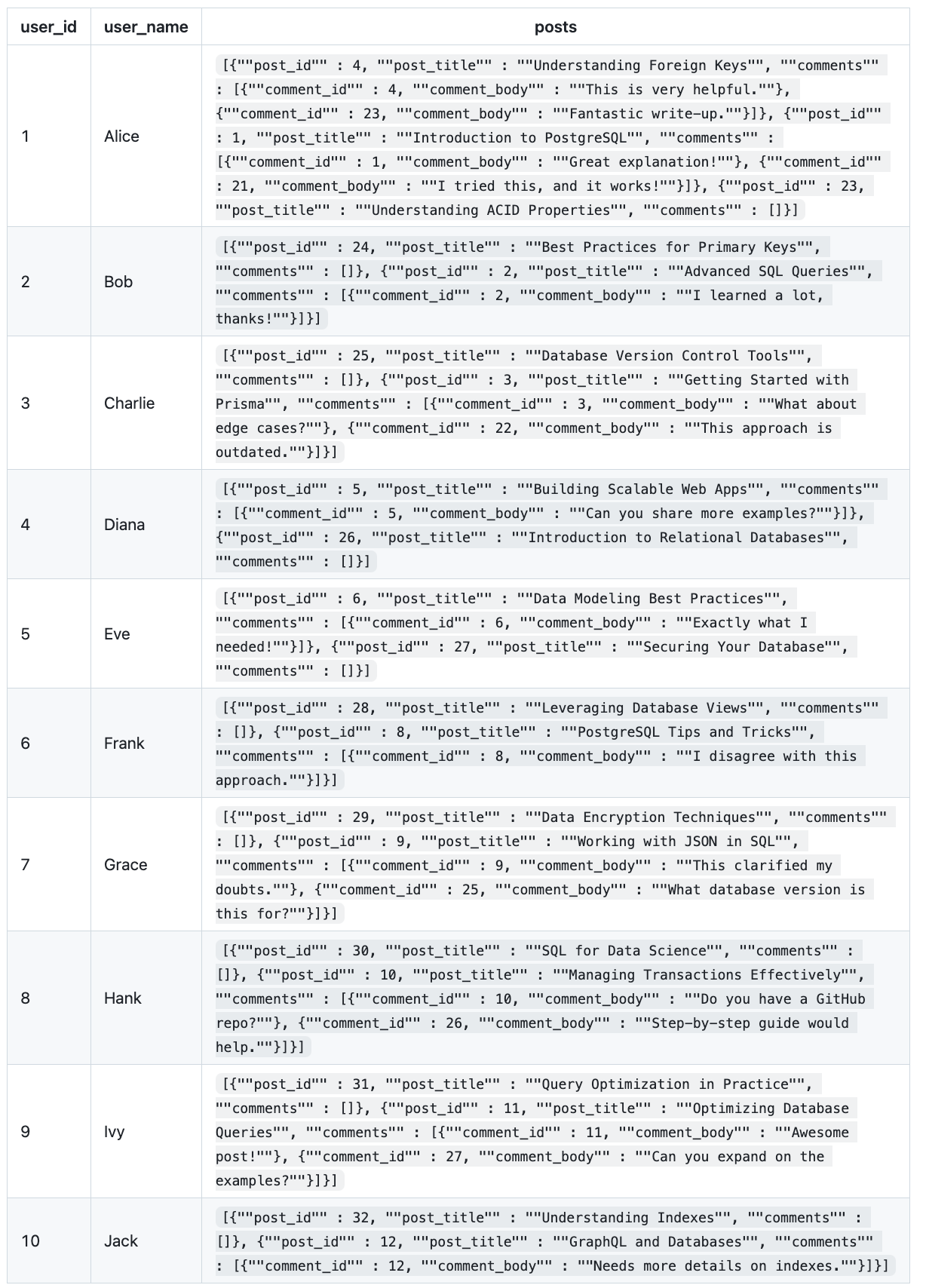
This data is similar to the one from the section about naive DB-level joins, except that:
- it no longer contains redundancies
- the posts are already formatted in JSON structures
While this query may yield better formatted results than the naive strategy, it also has become long and complex. Keep in mind we're still talking about a relatively simple scenario overall: joining three tables without additional factors most real-world applications are dealing with (e.g. filtering and pagination).
The evolution of JOIN strategies in Prisma ORM
When Prisma ORM was initially released in 2021, it implemented the application-level join strategy for all its relation queries.
This strategy works really well when the application server and database are located closely to each other, helps with portability across database engines and increases scalability of the overall system (since application-layer CPU is easier and cheaper to scale than DB-level CPU).
While the approach of application-level joins has served most developers well, it sometimes caused problems when application server and database couldn't be hosted closely to each other and the additional round trips negatively impacted overall query performance.
That's why we've added the smart DB-level joins as an alternative one year ago, so developers have the option to always choose the most performant join strategy for their individual use case.
Being able to use DB-level joins had been one of the most popular feature requests of Prisma ORM and has been received well by our community since it was released in Preview. Once this feature becomes generally available, DB-level joins will become the default join strategy Prisma ORM applies for its relation queries.
Community feedback is one of the major drivers that helps us prioritize what we're working on to improve Prisma ORM.
Conclusion
Figuring out the most performant way to join data from multiple tables in a database is a complicated topic. In this article, we looked at three different approaches, naive and smart joins on the DB-level as well as application-level joins.
Naive DB-level joins incur high CPU costs on the database server and lead to network overhead due to the unnecessary transfer of redundant data.
Application-level joins may be better suited for many scenarios due to their simplicity and cheap execution on the database-level. Systems using this strategy are also typically easier and less expensive to scale.
Finally, smart DB-level joins are solving the issues of redundancy, can return data in nested structures tailored for the needs of an application developer and overall have a higher likelihood to be better optimized by the database engine.