New Datamodel Syntax: More Schema Control & Simpler Migration

Prisma's latest release features an improved datamodel syntax. It removes many of the opinionated decisions Prisma used to make about the database layout and enables more control for developers.
⚠️ This article is outdated as it relates to Prisma 1 which is now deprecated. To learn more about the most recent version of Prisma, read the documentation. ⚠️
Over the last months, we have worked with the community to define an improved datamodel specification for Prisma. This new version is called datamodel v1.1 and is available in today's stable release. Check out the docs here.
As of today, Prisma's public Demo servers will be using the new datamodel syntax. Check out the docs or this tutorial video to learn how to upgrade your existing projects.
A more flexible approach to data modelling
A datamodel is the foundation for every Prisma project. It serves as the foundation for the schema of the underlying database.
The current datamodel is opinionated about the database layout, e.g. for relations, naming of tables/columns or system fields. The new datamodel syntax lifts many limitations so that developers have more control over their schema.
More control over your database layout
Here are a few things enabled by the new datamodel syntax:
- Specify whether a relation should use a relation table or foreign keys
- Model/field names can differ from the names of the underlying tables/columns
- Use any field as
idfield and "bring your own ID" - Use any field as
createdAtorupdatedAtfields
Simpler migrations & improved introspection
In previous Prisma versions, developers had to decide whether Prisma should perform database migrations for them, by setting the migrations flag in PRISMA_CONFIG.
The migrations flag has been removed in the latest Prisma version, meaning developers can now at all times either migrate the database manually or use Prisma for the migration.
We have also invested a lot into the introspection of existing databases, enabling smooth workflows for developers that are using Prisma with a legacy database or need to perform manual migrations at some point.
What's new in the improved datamodel syntax?
Map model and field names to the underlying tables and columns
With the old datamodel syntax, tables and columns are always named exactly after the models and fields in your datamodel. Using the new @db directive, you can control what tables and columns should be called in the underlying database:
type User @db(name: "user") {
id: ID! @id
name: String! @db(name: "full_name")
}CREATE TABLE "default$default"."user" (
"id" varchar(25) NOT NULL,
"full_name" text NOT NULL,
PRIMARY KEY ("id")
);In this case, the underlying table will be called user and the column full_name.
Decide how a relation is represented in the database schema
The old datamodel is opinionated about relations in the database schema: they're always represented as relation tables.
On the one hand, this makes it possible to easily migrate any existing relation to a many-to-many-relation without extra work. However, there might be a performance penalty to pay for this flexibility because relation tables are often more expensive to query.
While 1
and 1 relations can now be represented via foreign keys, m relations will keep being represented as relation tables.
With the new datamodel, developers can take full control over expressing a relation in the underlying database. There are two options:
- Represent a relation via inline references (i.e. foreign keys)
- Represent a relation via a relation table
Here is an example with two relations (one is inline, the other uses a relation table):
type User {
id: ID! @id
profile: Profile! @relation(link: INLINE)
posts: [Post!]! @relation(link: TABLE)
}
type Profile {
id: ID! @id
user: User!
}
type Post {
id: ID! @id
author: User!
}CREATE TABLE "default$default"."User" (
"id" varchar(25) NOT NULL,
"profile" varchar(25),
PRIMARY KEY ("id")
);
CREATE TABLE "default$default"."Profile" (
"id" varchar(25) NOT NULL,
PRIMARY KEY ("id")
);
CREATE TABLE "default$default"."Post" (
"id" varchar(25) NOT NULL,
PRIMARY KEY ("id")
);
CREATE TABLE "default$default"."_PostToUser" (
"A" varchar(25) NOT NULL,
"B" varchar(25) NOT NULL
);In the case of the inline relation, the placement of the @relation(link: INLINE) directive determines on which end of the relation the foreign key is being stored, in this example it's stored in the User table.
Use any field as id, createdAt or updatedAt
With the old datamodel, developers were required to use reserved fields if they wanted to automatically generate unique IDs or track when a record was created/last updated.
With the new @id, @createdAt and @updatedAt directives, it is now possible to add this functionality to any field of a model:
type User {
myID: ID! @id
myCreatedAt: DateTime! @createdAt
myUpdatedAt: DateTime! @updatedAt
}CREATE TABLE "test$devasdas"."User" (
"myID" varchar(25) NOT NULL,
"myCreatedAt" timestamp(3) NOT NULL,
"myUpdatedAt" timestamp(3) NOT NULL,
PRIMARY KEY ("myID")
);More flexible IDs
The current datamodel always uses CUIDs to generate and store globally unique IDs for database records. The datamodel v1.1 now makes it possible to maintain custom IDs as well as to use other ID types (e.g. integers, sequences, or UUIDs).
Getting started with the new datamodel syntax
We prepared two short tutorials for you to explore the new datamodel:
- Option A: Upgrade an old Prisma project to the new datamodel syntax
- Option B: Get started from scratch with the new datamodel syntax
For more extensive tutorials and instructions for getting started with an existing database, visit the docs.
Prerequisite: Install the latest Prisma CLI
To install the latest version of the Prisma CLI, run:
npm install -g prismaWhen running Prisma with Docker, you need to upgrade its Docker image to
1.31.
Option A: Upgrade from an older Prisma version
When upgrading your existing Prisma projects, you can use simply run prisma introspect to generate the datamodel with the new syntax. The exact process is described with an example in the following sections and this video:
1. Old datamodel setup
Assume you already have a running Prisma project that uses an (old) datamodel.
2. Upgrade your Prisma server
In the Docker Compose file used to deploy your Prisma server, make sure to use the latest 1.31 Prisma version for the prismagraphql/prisma image. For example:
version: '3'
services:
prisma:
image: prismagraphql/prisma:1.31
restart: always
ports:
- '4466:4466'
environment:
PRISMA_CONFIG: |
port: 4466
databases:
default:
connector: postgres
host: localhost
user: prisma
password: prisma
port: '5432'Now upgrade the running Prisma server:
docker-compose up -d3. Generate new datamodel via introspection
If you're now running prisma deploy, your Prisma CLI will throw an error because you're trying to deploy a datamodel in the old syntax to an updated Prisma server.
The easiest way to fix these errors is by generating a datamodel written in the new syntax via introspection. Run the following command inside the directory where your prisma.yml is located:
prisma introspectThis introspects your database and generates another datamodel with the new syntax, called datamodel-TIMESTAMP.prisma (e.g. datamodel-1554394432089.prisma). For the example from above, the following datamodel is generated:
type User {
id: ID! @id
createdAt: DateTime! @createdAt
updatedAt: DateTime! @updatedAt
name: String
email: String! @unique
role: Role @default(value: USER)
posts: [Post]
profile: Profile @relation(link: TABLE)
}
type Profile {
id: ID! @id
createdAt: DateTime! @createdAt
updatedAt: DateTime! @updatedAt
user: User!
bio: String!
}
type Post {
id: ID! @id
createdAt: DateTime! @createdAt
updatedAt: DateTime! @updatedAt
title: String!
published: Boolean! @default(value: false)
author: User! @relation(link: TABLE)
categories: [Category]
}
type Category {
id: ID! @id
createdAt: DateTime! @createdAt
updatedAt: DateTime! @updatedAt
name: String!
posts: [Post]
}
enum Role {
USER
ADMIN
}4. Deploy new datamodel
The final step is to delete the old datamodel.prisma file and rename your generated datamodel to datamodel.prisma (so that the datamodel property in your prisma.yml points to the generated file that's using the new syntax).
Once that's done, you can run:
prisma deploy5. Optimize your database schema
Because the introspection didn't change anything about your database layout, all relations are still represented as relation tables. If you want to learn how you can migrate the old 1
and 1 relations to use foreign keys, check out the docs here.Option B: Starting from scratch
After having learned how to upgrade existing Prisma projects, we'll now walk you through a simple setup where we're starting out from scratch.
1. Create a new Prisma project
Let's start by setting up a new Prisma project:
prisma init hello-datamodelIn the interactive wizard, select the following:
- Select Create new database
- Select PostgreSQL (or MySQL, if you prefer)
- Select a client in your preferred language (optional as we won't use the client)
Before launching the Prisma server and the database via Docker, enable port mapping for your database. This will later allow you to connect to the database using a local DB client (such as Postico or TablePlus).
In the generated docker-compose.yml, uncomment the following lines in the Docker image configuration of the database:
ports:
- '5432:5432'ports:
- '3306:3306'2. Define datamodel
Let's define a datamodel that takes advantage of the new Prisma features. Open datamodel.prisma and replace the contents with the following:
type User @db(name: "user") {
id: ID! @id
createdAt: DateTime! @createdAt
email: String! @unique
name: String
role: Role @default(value: USER)
posts: [Post!]!
profile: Profile @relation(link: INLINE)
}
type Profile @db(name: "profile") {
id: ID! @id
user: User!
bio: String!
}
type Post @db(name: "post") {
id: ID! @id
createdAt: DateTime! @createdAt
updatedAt: DateTime! @updatedAt
author: User!
published: Boolean! @default(value: false)
categories: [Category!]! @relation(link: TABLE, name: "PostToCategory")
}
type Category @db(name: "category") {
id: ID! @id
name: String!
posts: [Post!]! @relation(name: "PostToCategory")
}
type PostToCategory @db(name: "post_to_category") @relationTable {
post: Post
category: Category
}
enum Role {
USER
ADMIN
}Here are some important bits about this datamodel definition:
- Each model is mapped a table that's named after the model but lowercased using the
@dbdirective. - There are the following relations:
- 1 between
UserandProfile - 1 between
UserandPost - n between
PostandCategory
- 1 between
- The 1 relation between
UserandProfileis annotated with@relation(link: INLINE)on theUsermodel. This meansuserrecords in the database have a reference to aprofilerecord if the relation is present (because theprofilefield is not required, the relation might just beNULL). An alternative toINLINEisTABLEin which case Prisma would track the relation via a dedicated relation table. - The 1 relation between
UserandPostis is tracked inline the relation via theauthorcolumn of theposttable, i.e. the@relation(link: INLINE)directive is inferred on theauthorfield of thePostmodel. - The n relation between
PostandCategoryis tracked via a dedicated relation table calledPostToCategory. This relation table is part of the datamodel and annotated with the@relationTabledirective. - Each model has an
idfield annotated with the@iddirective. - For the
Usermodel, the database automatically tracks when a record is created via the field annotated with the@createdAtdirective. - For the
Postmodel, the database automatically tracks when a record is created and updated via the fields annotated with the@createdAtand@updatedAtdirectives.
3. Deploy the datamodel
In the next step, Prisma will map this datamodel to the underlying database:
prisma deploy4. View and edit the data in Prisma Admin
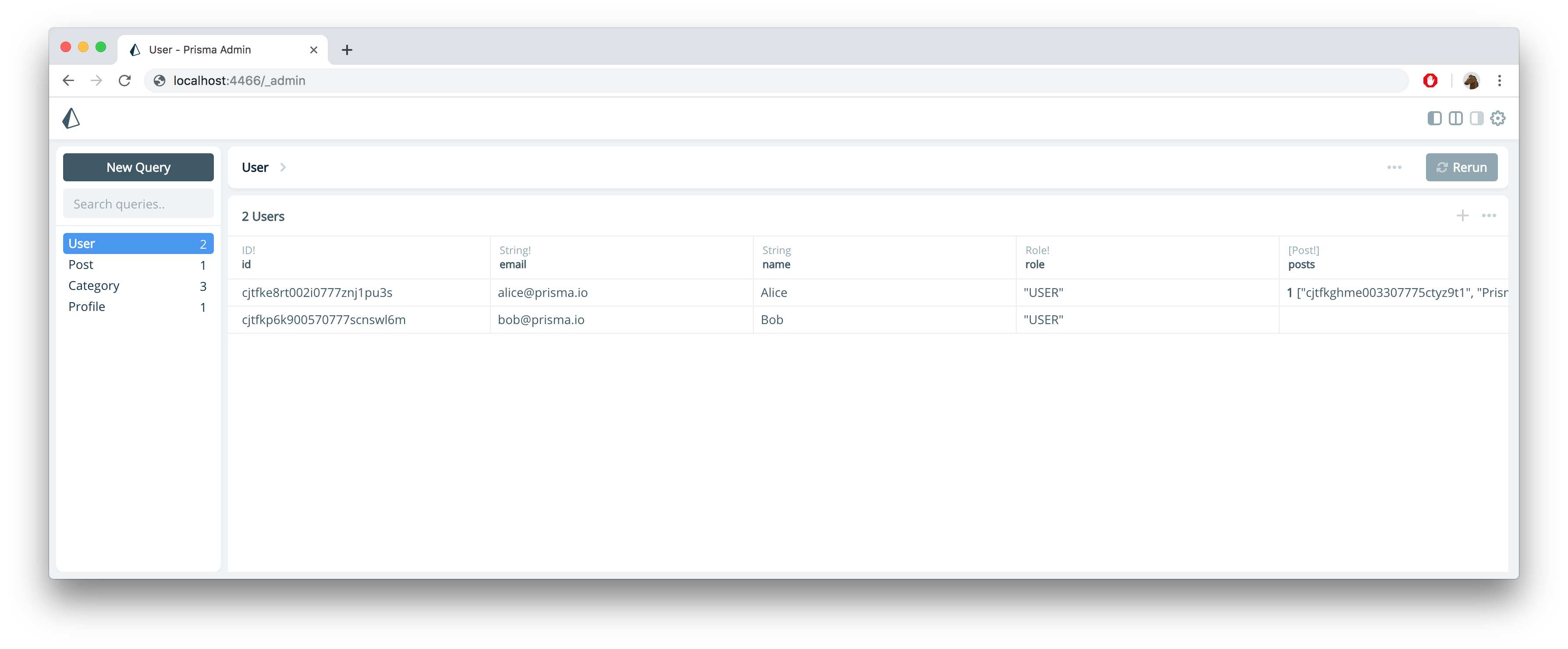
From here on, you can use the Prisma client if you want to access the data in your database programmatically. In the following, we'll highlight how to use Prisma Admin to interact with the data.
Visit the docs to learn how you can connect to the database using TablePlus and explore the underlying database schema.
To access your data in Prisma Admin, you need to navigate to the Admin endpoint of your Prisma project: http://localhost:4466/_admin
Share you feedback and ideas
While the new datamodel syntax already incorporates many features requested by our community, we still see opportunities to improve it even further. For example, the datamodel doesn't yet provide multi-column indices and polymorphic relations.
We are currently working on a new data modeling language that will be a variation of the currently used SDL.
We'd love hear what you think of the new datamodel. Please share your feedback by opening an issue in the feedback repo or join the conversation on Spectrum.