February 06, 2018
GraphQL Basics: Demystifying the `info` Argument in GraphQL Resolvers

Structure and Implementation of GraphQL Servers (Part III)

If you’ve written a GraphQL server before, chances are you’ve already come across the info object that gets passed into your resolvers. Luckily in most cases, you don’t really need to understand what it actually does and what its role is during query resolution.
However, there are a number of edge cases where the info object is the cause of a lot of confusion and misunderstandings. The goal of this article is to take a look under the covers of the info object and shed light on its role in the GraphQL execution process.
This article assumes you’re already familiar with the basics of how GraphQL queries and mutations are resolved. If you feel a bit shaky in this regard, you should definitely check out the previous articles of this series: Part I: The GraphQL Schema (required) Part II: The Network Layer (optional)
Structure of the info object
Recap: The signature of GraphQL resolvers
A quick recap, when building a GraphQL server with GraphQL.js, you have two major tasks:
- Define your GraphQL schema (either in SDL or as a plain JS object)
- For each field in your schema, implement a resolver function that knows how to return the value for that field
A resolver function takes four arguments (in that order):
parent: The result of the previous resolver call (more info).args: The arguments of the resolver’s field.context: A custom object each resolver can read from/write to.info: That’s what we’ll discuss in this article.
Here is an overview of the execution process of a simple GraphQL query and the invocations of the belonging resolvers. Because the resolution of the 2nd resolver level is trivial, there is no need to actually implement these resolvers — their return values are automatically inferred by GraphQL.js:
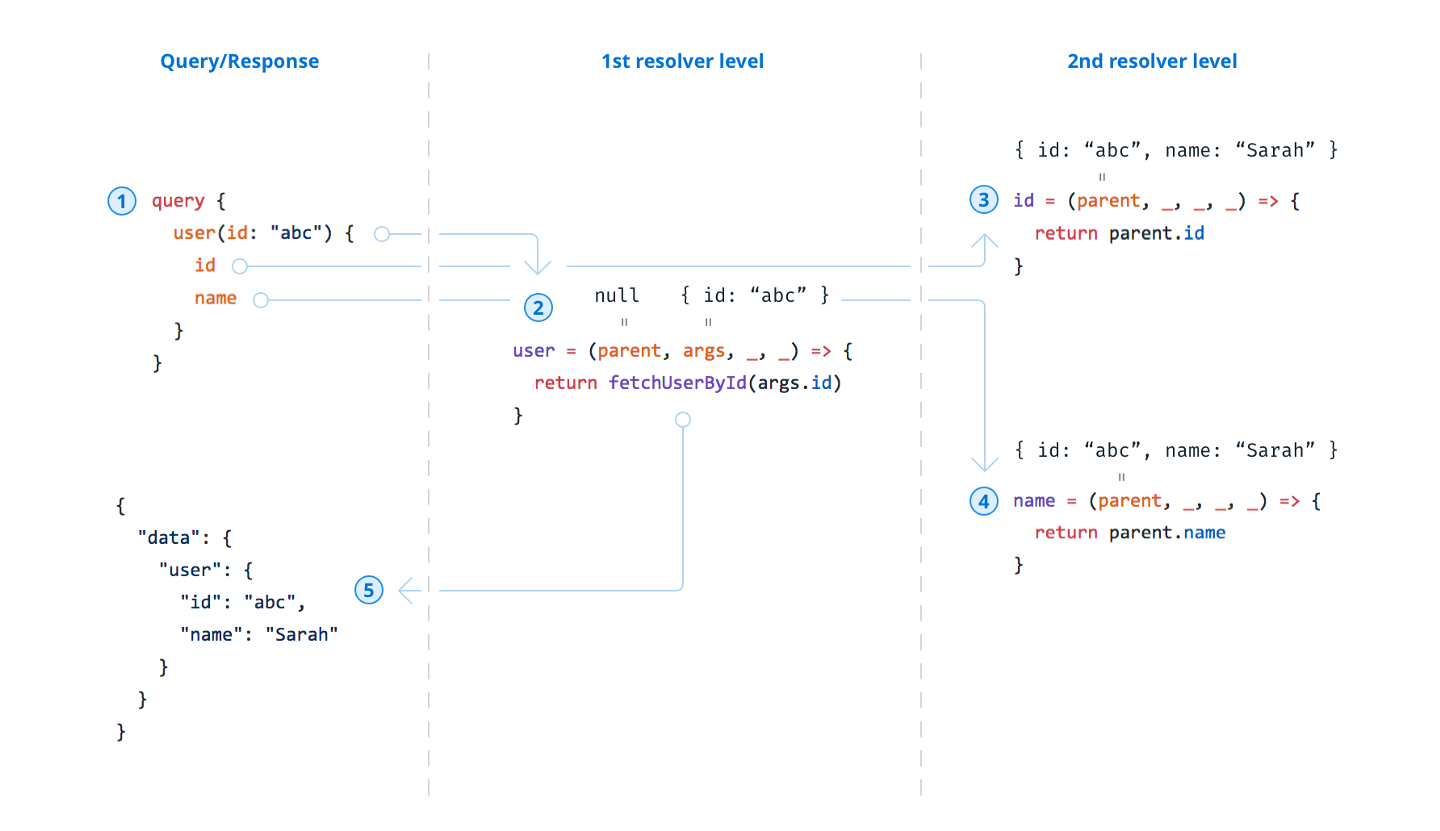
Overview of the parent and args argument in the GraphQL resolver chain
info contains the query AST and more execution information
Those curios about the structure and the role of the info object are left in the dark. Neither the official spec, nor the documentation are mentioning it at all. There used to be a GitHub issue requesting better documentation for it, but that was closed without notable action. So, there’s no other way than digging into the code.
On a very high-level, it can be stated that the info object contains the AST of the incoming GraphQL query. Thanks to that, the resolvers know which fields they need to return.
To learn more about what query ASTs look like, be sure to check out Christian Joudrey’s fantastic article Life of a GraphQL Query — Lexing/Parsing as well as Eric Baer’s brilliant talk GraphQL Under the Hood.
To understand the structure of info, let’s take a look at its Flow type definition:
Here’s an overview and quick explanation for each of these keys:
fieldName: As mentioned before, each field in your GraphQL schema needs to be backed by a resolver. ThefieldNamecontains the name for the field that belongs to the current resolver.fieldNodes: An array where each object represents a field in the remaining selection set.returnType: The GraphQL type of the corresponding field.parentType: The GraphQL type to which this field belongs.path: Keeps track of the fields that were traversed until the current field (i.e. resolver) was reached.schema: TheGraphQLSchemainstance representing your executable schema.fragments: A map of fragments that were part of the query document.rootValue: TherootValueargument that was passed to the execution.operation: The AST of the entire query.variableValues: A map of any variables that were provided along with the query corresponds to the variableValues argument.
Don’t worry if that still seems abstract, we’ll see examples for all of these soon.
Field-specific vs Global
There is one interesting observation to be made regarding the keys above. A key on the info object is either field-specific or global.
Field-specific simply means that the value for that key depends on the field (and its backing resolver) to which the info object is passed. Obvious examples are fieldName, rootType and parentType. Consider the author field of the following GraphQL type:
The fieldName for that field is just author, the returnType is User! and the parentType is Query.
Now, for feed these values will of course be different: the fieldName is feed, returnType is [Post!]! and the parentType is also Query.
So, the values for these three keys are field-specific. Further field-specific keys are: fieldNodes and path. Effectively, the first five keys of the Flow definition above are field-specific.
Global, on the other hand, means the values for these keys won’t change — no matter which resolver we’re talking about. schema, fragments, rootValue, operation and variableValues will always carry the same values for all resolvers.
A simple example
Let’s now go ahead and see an example for the contents of the info object. To set the stage, here is the schema definition we’ll use for this example:
Assume the resolvers for that schema are implemented as follows:
Note that the
Post.titleresolver is not actually required, we still include it here to see what theinfoobject looks like when the resolver gets called.
Now consider the following query:
For the purpose of brevity, we’ll only discuss the resolver for the Query.author field, not the one for Post.title (which is still invoked when the above query is executed).
If you want to play around with this example, we prepared a repository with a running version of the above schema so you have something to experiment with!
Next, let’s take a look at each of the keys inside the info object and see what they look like when the Query.author resolver is invoked (you can find the entire logging output for the info object here).
fieldName
The fieldName is simply author.
fieldNodes
Remember that fieldNodes is field-specific. It effectively contains an excerpt of the query AST. This excerpt starts at the current field (i.e. author) rather than at the root of the query. (The entire query AST which starts at the root is stored in operation, see below).
returnType & parentType
As seen before, returnType and parentType are fairly trivial:
path
The path tracks the fields which have been traversed until the current one. For Query.author, it simply looks like"path": { "key": "author" }.
For comparison, in the Post.title resolver, the path looks as follows:
The remaining five fields fall into the “global” category and therefore will be identical for the
Post.titleresolver.
schema
The schema is a reference to the executable schema.
fragments
fragments contains fragment definitions, since the query document doesn’t have any of those, it’s just an empty map: {}.
rootValue
As mentioned before, the value for the rootValue key corresponds to the rootValue argument that’s passed to the graphql execution function in the first place. In the case of the example, it’s just null.
operation
operation contains the full query AST of the incoming query. Recall that among other information, this contains the same values we saw for fieldNodes above:
variableValues
This key represents any variables that have been passed for the query. As there are no variables in our example, the value for this again is just an empty map: {}.
If the query was written with variables:
The variableValues key would simply have the following value:
The role of info when using GraphQL bindings
As mentioned in the beginning of the article, in most scenarios you don’t need to worry at all about the info object. It just happens to be part of your resolver signatures, but you’re not actually using it for anything. So, when does it become relevant?
Passing info to binding functions
If you’ve worked with GraphQL bindings before, you’ve seen the info object as part of the generated binding functions. Consider the following schema:
Using graphql-binding, you can now send the available queries and mutations by invoking dedicated binding functions rather than sending over raw queries and mutations.
For example, consider the following raw query, retrieving a specific User:
Achieving the same with a binding function would look as follows:
With the invocation of the user function on the binding instance and by passing the corresponding arguments, we convey exactly the same information as with the raw GraphQL query above.
A binding function from graphql-binding takes three arguments:
args: Contains the arguments for the field (e.g. theusernamefor thecreateUsermutation above).context: Thecontextobject that’s passed down the resolver chain.info: Theinfoobject. Note that rather than an instance ofGraphQLResolveInfo(which is the type of info) you can also pass a string that simply defines the selection set.
Mapping application schema to database schema with Prisma
Another common use case where the info object can cause confusion is the implementation of a GraphQL server based on Prisma and prisma-binding.
In that context, the idea is to have two GraphQL layers:
- the database layer is automatically generated by Prisma and provides a generic and powerful CRUD API
- the* application layer* defines the GraphQL API that’s exposed to client applications and tailored to your application’s needs
As a backend developer, you’re responsible to define the application schema for the application layer and implement its resolvers. Thanks to prisma-binding, the implementation of the resolvers merely is a process of delegating incoming queries to the underlying database API without major overhead.
Let’s consider a simple example — say you’re starting out with the following data model for your Prisma database service:
The database schema that Prisma generates based on this data model looks similar to this:
Now, assume you want to build an application schema looking similar to this:
The feed query not only returns a list of Post elements, but is also able to return the count of the list. Note that it optionally takes an authorId which filters the feed to only return Post elements written by a specific User.
A first intuition to implement this application schema might look as follows.
IMPLEMENTATION 1: This implementation looks correct but has a subtle flaw:
This implementation seems reasonable enough. Inside the feed resolver, we’re constructing the authorFilter based on the potentially incoming authorId. The authorFilter is then used to execute the posts query and retrieve the Post elements, as well as the postsConnection query which gives access to the count of the list.
It would also be possible to retrieve the actual Post elements using just the postsConnection query. To keep things simple, we’re still using the posts query for that and leave the other approach as an exercise to the attentive reader.
In fact, when starting your GraphQL server with this implementation, things will seem good at first sight. You’ll notice that simple queries are served properly, for example the following query will succeed:
It isn’t until you’re trying to retrieve the author of the Post elements when you’re running into an issue:
All right! So, for some reason the implementation doesn’t return the author and that triggers an error "Cannot return null for non-nullable Post.author." because the Post.author field is marked as required in the application schema.
Let’s take a look again at the relevant part of the implementation:
Here is where we retrieve the Post elements. However, we’re not passing a selection set to the posts binding function. If no second argument is passed to a Prisma binding function, the default behaviour is to query all scalar fields for that type.
This indeed explains the behaviour. The call to ctx.db.query.posts returns the correct set of Post elements, but only their id and title values — no relational data about the authors.
So, how can we fix that? What’s needed obviously is a way to tell the posts binding function which fields it needs to return. But where does that information reside in the context of the feed resolver? Can you guess that?
Correct: Inside the info object! Because the second argument for a Prisma binding function can either be a string or an info object, let’s just pass the info object which gets passed into the feed resolver on to the posts binding function.
This query fails with IMPLEMENTATION 2: “Field ‘posts’ of type ‘Post’ must have a sub selection.”
With this implementation however, no request will be properly served. As an example, consider the following query:
The error message "Field ‘posts’ of type ‘Post’ must have a sub selection." is produced by line 8 of the above implementation.
So, what is happening here? The reason why this fails because the field-specific keys in the info object don’t match up with the posts query.
Printing the info object inside the feed resolver sheds more light on the situation. Let’s consider only the field-specific information in fieldNodes:
This JSON object can be represented as as string selection set as well:
Now it all makes sense! We’re sending the above selection set to the posts query of the Prisma database schema which of course is not aware of the feed and count fields. Admittedly, the error message that’s produced is not super helpful but at least we understand what’s going on now.
So, what’s the solution to this problem? One way to approach this issue would be to manually parse out the correct part of the selection set of fieldNodes and pass it to the posts binding function (e.g. as a string).
However, there is a much more elegant solution to the problem, and that is to implement dedicated resolver for the Feed type from the application schema. Here is what the proper implementation looks like.
IMPLEMENTATION 3: This implementation fixes the above issues
This implementation fixes all the issues that were discussed above. There are few things to note:
- In line 8, we’re now passing a string selection set (
{ id }) as a second argument. This is just for efficiency since otherwise all the scalar values would be fetched (which wouldn’t make a huge difference in our example) where we only need the IDs. - Rather than returning
postsfrom theQuery.feedresolver, we’re returningpostIdswhich is just an array of IDs (represented as strings). - In the
Feed.postsresolver, we can now access thepostIdswhich were returned by the parent resolver. This time, we can make use the incominginfoobject and simply pass it on to thepostsbinding function.
If you want to play around with this example, you can check out this repository which contains a running version of the above example. Feel free to try out the different implementations mentioned in this article and observe the behaviour yourself!
Summary
In this article, you got deep insights into the info object which is used when implementing a GraphQL API based on GraphQL.js.
The info object is not officially documented — to learn more about it you need to dig into the code. In this tutorial, we started by outlining its internal structure and understanding its role in GraphQL resolver functions. We then covered a few edge cases and potential traps where a deeper understanding of info is required.
All the code that was shown in this article can be found in corresponding GitHub repositories so you can experiment and observe the behaviour of the info object yourself.
Don’t miss the next post!
Sign up for the Prisma Newsletter