
Understanding GraphQL schema stitching (Part I)

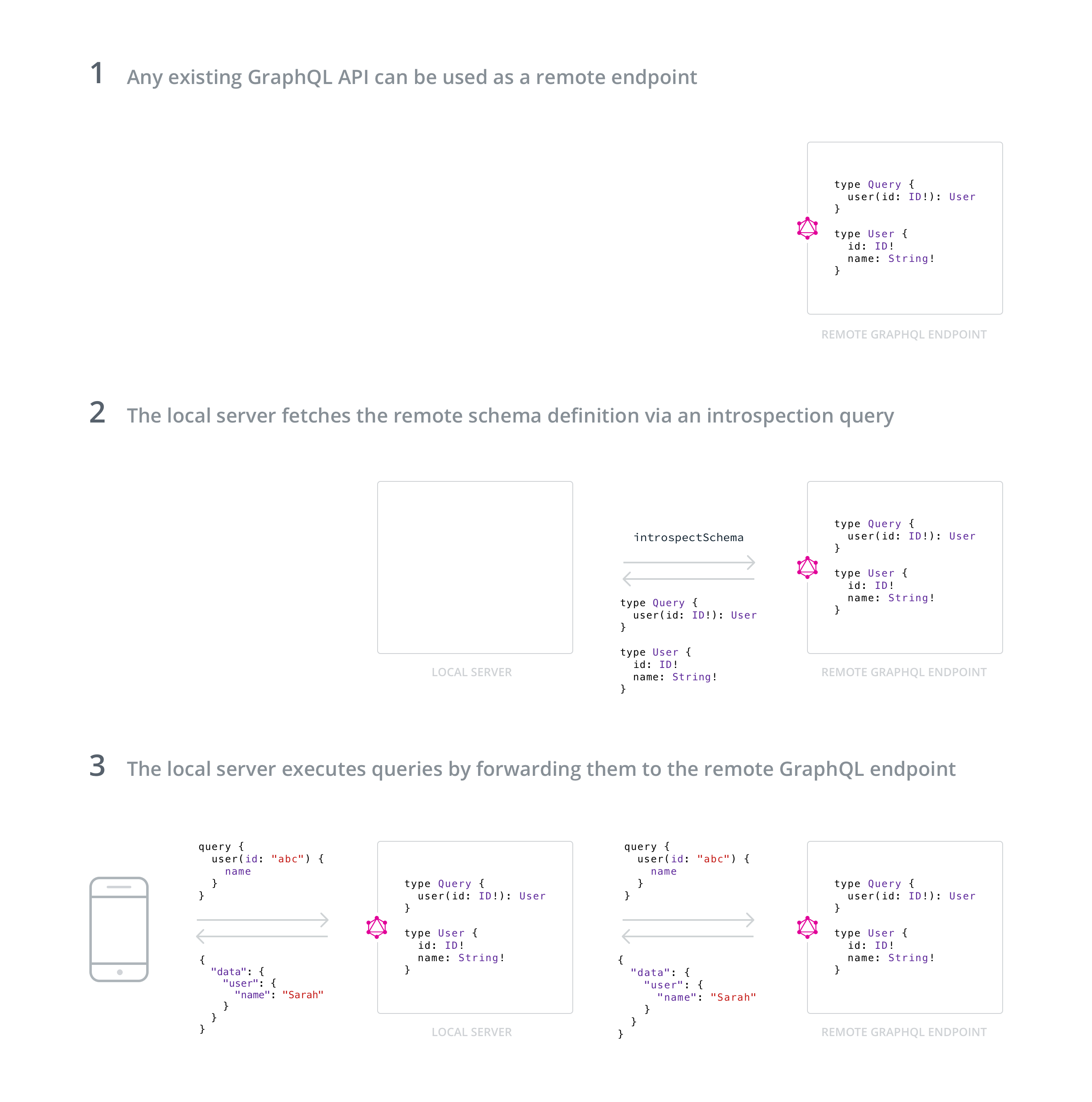
In this article, we want to understand how we can use any existing GraphQL API and expose it through our own server. In that setup, our server simply forwards the GraphQL queries and mutations it receives to the underlying GraphQL API. The component responsible for forwarding these operations is called a remote (executable) schema.
Remote schemas are the foundation for a set of tools and techniques referred to as schema stitching, a brand new topic in the GraphQL community. In the following articles, we’ll discuss the different approaches to schemas stitching in more detail.
Recap: GraphQL Schemas
In a previous article, we already covered the basic mechanics and inner workings of the GraphQL schema. Let’s do a quick recap!
Before we begin, it’s important to disambiguate the term GraphQL schema, since it can mean a couple of things. For the context of this article, we’ll mostly use the term to refer to an instance of the GraphQLSchema class, which is provided by the GraphQL.js reference implementation and used as the foundation for GraphQL servers written in Node.js.
The schema is made up of two major components:
- Schema definition: This part is usually written in the GraphQL Schema Definition Language (SDL) and describes the capabilities of the API in an abstract way, so there’s not yet an actual implementation. In essence, the schema definition specifies what kinds of operations (queries, mutations, subscriptions) the server will accept. Note that for a schema definition to be valid it needs to contain the
Querytype — and optionally theMutationand/orSubscriptiontype. (When referring to a schema definition in code, corresponding variables are typically calledtypeDefs.) - Resolvers: Here is where the schema definition comes to life and receives its actual behaviour. Resolvers implement the API that’s specified by the schema definition. (For more info, refer to the last article.)
When a schema has a schema definition as well as resolver functions, we also refer to it as an executable schema. Note that an instance of
GraphQLSchemais not necessarily executable — it can be the case that it only contains a schema definition but doesn’t have any resolvers attached.
Here is what a simple example looks like, using the makeExecutableSchema function from graphql-tools:
typeDefs contains the schema definition, including the required Query and a simple User type. resolvers is an object containing the implementation for the user field defined on the Query type.
makeExecutableSchema now maps the fields from the SDL types in the schema definition to the corresponding functions defined in the resolvers object. It returns an instance of GraphQLSchema which we can now use to execute actual GraphQL queries, for example using the graphql function from GraphQL.js:
Because the graphql function is able to execute a query against an instance of GraphQLSchema, it’s also referred to as a GraphQL (execution) engine.
A GraphQL execution engine is a program (or function) that, given an executable schema and a query (or mutation), produces a valid response. Therefore, its main responsibility is to orchestrate the invocations of the resolver functions in the executable schema and properly package up the response data, according to the GraphQL specification.
With that knowledge, let’s dive into how we can create an executable instance of GraphQLSchema based on an existing GraphQL API.
Introspecting GraphQL APIs
One handy property of GraphQL APIs is that they allow for introspection. This means you can extract the schema definition of any GraphQL API by sending a so-called introspection query.
Considering the example from above, you could use the following query to extract all the types and their fields from a schema:
This would return the following JSON data:
As you can see, the information in this JSON object is equivalent to our SDL-based schema definition from above (actually it’s not 100% equivalent as we haven’t asked for the arguments on the fields, but we could simply extend the introspection query from above to include these as well).
Creating a remote schema
With the ability to introspect the schema of an existing GraphQL API, we can now simply create a new GraphQLSchema instance whose schema definition is identical to the existing one. That’s exactly the idea of makeRemoteExecutableSchema from graphql-tools.
makeRemoteExecutableSchema receives two arguments:
- A schema definition (which you can obtain using an introspection query seen above). Note that it’s considered best practice to download the schema definition already at development time and upload it to your server as a
.graphql-file rather than sending an introspection query at runtime (which results in a big performance overhead). - A Link that is connected to the GraphQL API to be proxied. In essence, this Link is a component that can forward queries and mutations to the existing GraphQL API — so it needs to know its (HTTP) endpoint.
The implementation of makeRemoteExecutableSchema is fairly straightforward from here. The schema definition is used as the foundation for the new schema. But what about the resolvers, where do they come from?
Obviously, we can’t download the resolvers in the same way we download the schema definition — there is no introspection query for resolvers. However, we can create new resolvers that are using the mentioned Link component to simply forward any incoming queries or mutations to the underlying GraphQL API.
Enough palaver, let’s see some code! Here is an example which is based on a Graphcool CRUD API for a type called User in order to create a remote schema which is then exposed through a dedicated server (using graphql-yoga):
Find the working example for this code here
For context, the CRUD API for the User type looks somewhat similar to this (the full version can be found here):
Remote schemas under the hood
Let’s investigate what databaseServiceSchemaDefinition and databaseServiceExecutableSchema from the above example look like under the covers.
Inspecting GraphQL schemas
The first thing to note is that both of them are instances of GraphQLSchema. However, the databaseServiceSchemaDefinition contains only the schema definition, while databaseServiceExecutableSchema is actually an executable schema — meaning it does have resolver functions attached to its types’ fields.
Using the chrome debugger, we can reveal the databaseServiceSchemaDefinition is a JavaScript object looking as follows:
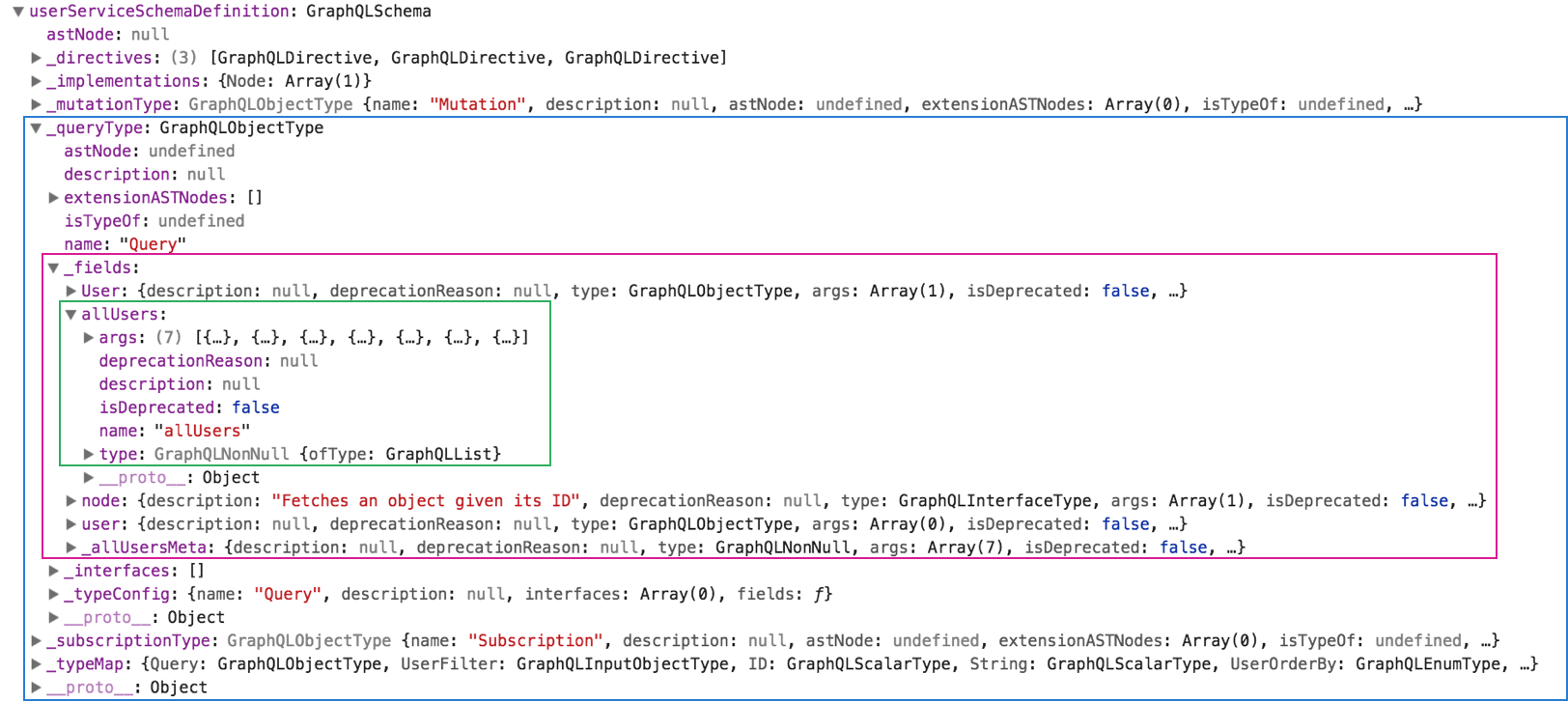 A non-executable instance of GraphQLSchema
A non-executable instance of GraphQLSchema
The blue rectangle shows the Query type with its properties. As expected, it has a field called allUsers (among others). However, in this schema instance there are no resolvers attached to the Query's fields— so it’s not executable.
Let’s also take a look at the databaseServiceExecutableSchema:
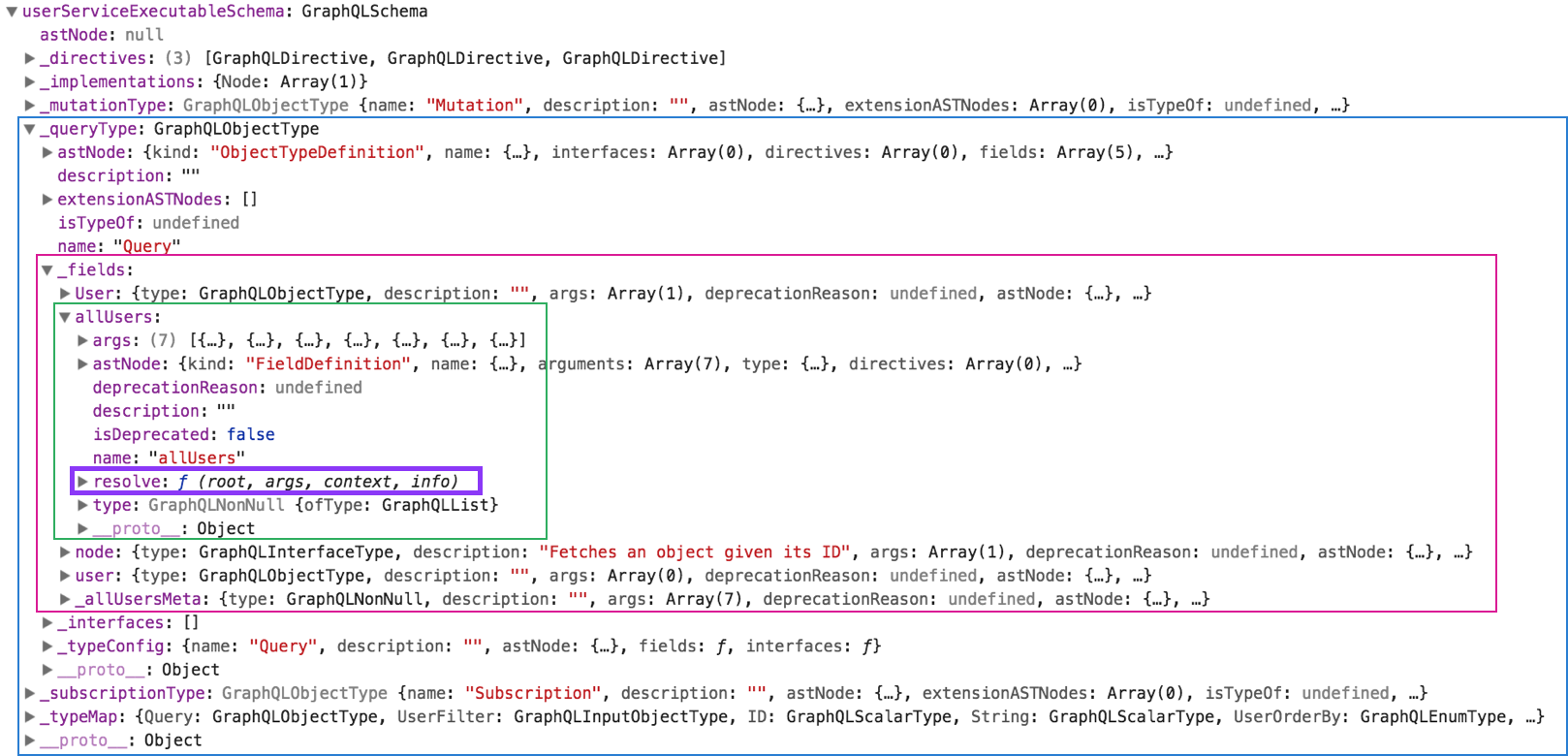 Executable Schema = Schema definition + Resolvers
Executable Schema = Schema definition + Resolvers
This screenshot looks very similar to the one we just saw — except that the allUsers field now has this resolve function attached to it. (This is also the case for the other fields on the Query type (User, node, user and _allUsersMeta), but not visible in the screenshot.)
We can go one step further and actually take a look at the implementation of the resolve function (note that this code was dynamically generated by makeRemoteExecutableSchema):
Line 12–16 is what’s interesting to us: a function called fetcher is invoked with three arguments: query, variables and context. The fetcher was generated based on the Link we provided earlier, it basically is a function that’s able to send a GraphQL operation to a specific endpoint (the one used to create the Link), which is exactly what it’s doing here. Notice that the actual GraphQL document that’s passed as the value for query in line 13 originates from the info argument passed into the resolver (see line 10). info contains the AST representation of the query .
Non-root resolvers don’t make network calls
In the same way that we explored the resolver function for the allUsers root field above, we can also investigate what the resolvers for the fields on the User type look like. We therefore need to navigate into the _typeMaps property of the databaseServiceExecutableSchema where we find the User type with its fields:
 The User type has two fields: id and name (both have an attached resolver function)
The User type has two fields: id and name (both have an attached resolver function)
Both fields (id and name) have a resolve function attached to them, here is their implementation that was generated by makeRemoteExecutableSchema (note that it’s identical for both fields):
Interestingly, this time the generated resolver does not use a fetcher function — in fact it doesn’t call out to the network at all. The result being returned is simply retrieved from the parent argument (line 10) that’s passed into the function.
Tracing resolver data in remote schemas
The tracing data for resolvers of remote executable schemas also confirm this finding. In the following screenshot, we extended the previous schema definition with an Article and Comment type (each also connected to the existingUser) so we can send a more deeply nested query.
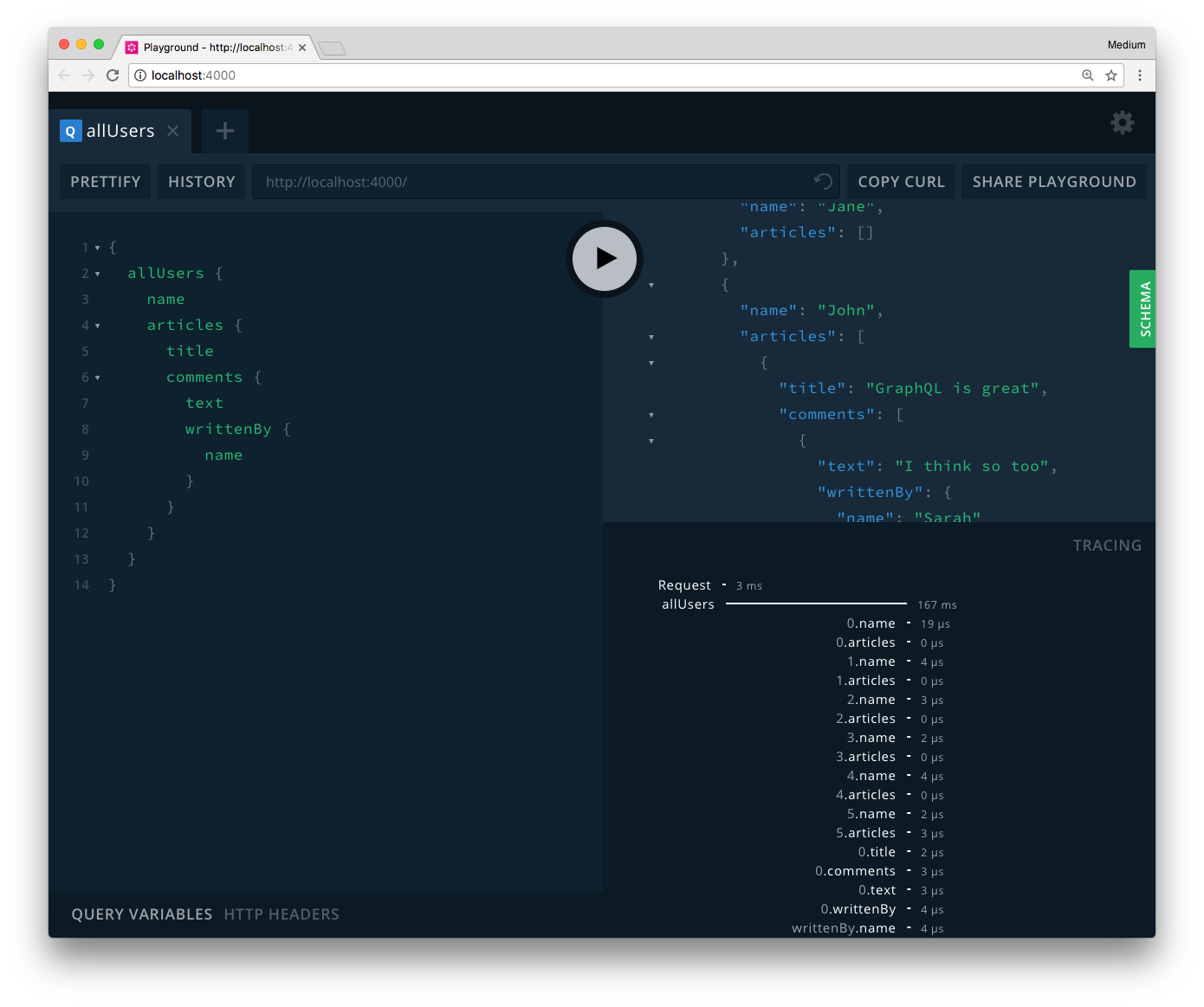 GraphQL Playgrounds support displaying tracing data for resolvers out-of-the-box (bottom right)
GraphQL Playgrounds support displaying tracing data for resolvers out-of-the-box (bottom right)
It’s very apparent from the tracing data that only the root resolver (for the allUsers field) takes notable time (167 milliseconds). All remaining resolvers responsible for returning data for non-root fields only take a few microseconds to be executed. This can be explained with the observation we made earlier that root resolvers use the fetcher to forward the received query while all non-root resolvers simple return their data based on the incoming parent argument.
Resolver strategies
When implementing the resolver functions for a schema definition, there are multiple ways how to this can be approached.
Standard pattern: Type level resolving
Consider the following schema definition:
Based on the Query type, it is possible to send the following query to the API:
How would the corresponding resolvers typically be implemented? A standard approach for this looks as follows (assume functions starting with fetch in this code are loading resources from a database):
With this approach, we’re resolving on a type level. This means that the actual object for a specific query (e.g. a particular Article) is fetched before any resolvers of the Article type are called.
Consider the resolver invocations for the query above:
- The
Query.userresolver is called and loads a specificUserobject from the database. Notice that it will load all scalar fields of theUserobject, includingidandnameeven though these have not been requested in the query. It does not load anything forarticlesyet though — this is what’s happening in the next step. - Next, the
User.articlesresolver is invoked. Notice that the input argumentparentis the return value from the previous resolver, so it’s a fullUserobject which allows the resolver to access theUser’sidto load theArticleobjects for it.
If you have trouble following this example, make sure to read the last article on GraphQL schemas.
Remote executable schemas use a multi-level resolver approach
Let’s now think about the remote schema example and its resolvers again. We learned that when executing a query using a remote executable schema, the datasource is only hit once, in the root resolver (where we found the fetcher – see screenshot above). All other resolvers only return the canonical result based on the incoming parent argument (which is a subpart of the result of the initial root resolver invocation).
But how does that work? It seems that the root resolver fetches all needed data in a single resolver — but isn’t this super inefficient? Well, it indeed would be very inefficient, if we always load all object fields including all relational data. So how can we only load the data specified in the incoming query?
This is why the root resolver of remote executable schemas makes use of the available info argument which contains the query information. By looking at the selection set of the actual query, the resolver doesn’t have to load all fields of an object but instead only loads the fields it needs. This “trick” is what makes it still efficient to load all data in a single resolver.
Summary
In this article, we learned how to create a proxy for any existing GraphQL API using makeRemoteExecutableSchema from graphql-tools. This proxy is called a remote executable schema and running on your own server. It simply forwards any queries it receives to the underlying GraphQL API.
We also saw that this remote executable schema is implemented using a multi-level resolver where nested data is fetched a single time by the first resolver rather than multiple times on a type level.
There is still a lot to discover about remote schemas: How does this relate to schema stitching? How does this work with GraphQL subscriptions? What happens to my context object? Let us know in the comments what you’d like to learn next! 👋
Don’t miss the next post!
Sign up for the Prisma Newsletter