Prisma ORM Now Lets You Choose the Best Join Strategy (Preview)

Fetching related data from multiple tables in SQL databases can get expensive. Prisma ORM now lets you choose between database-level and application-level joins so that you can pick the most performant approach for your relation queries.
Contents
- New in Prisma ORM: Choose the best Join strategy 🎉
joinvsquery— when to use which?- Understanding relations in SQL databases
- What's happening under the hood?
- Try it out and share your feedback
New in Prisma ORM: Choose the best join strategy 🎉
Support for database-level joins has been one of the most requested features in Prisma ORM and we're excited to share that it's now available as another query strategy!

For any relation query with include (or select), there is now a new option on the top-level called relationLoadStrategy. This option accepts one out of two possible values:
join(default): Uses the database-level join strategy to merge the data in the database.query: Uses the application-level join strategy by sending multiple queries to individual tables and merging the data in the application layer.
To enable the new relationLoadStrategy, you'll first need to add the preview feature flag to the generator block of your Prisma Client:
generator client {
provider = "prisma-client-js"
previewFeatures = ["relationJoins"]
}Note: The
relationLoadStrategyis only available for PostgreSQL and MySQL databases.
Once that's done, you'll need to re-run prisma generate for this change to take effect and pick a relation load strategy in your queries.
Here is an example that uses the new join strategy:
const usersWithPosts = await prisma.user.findMany({
relationLoadStrategy: "join", // or "query"
include: {
posts: true,
},
});model User {
id Int @id @default(autoincrement())
name String?
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
author User @relation(fields: [authorId], references: [id])
authorId Int
}Note that because "join" is the default, the relationLoadStrategy option could technically also be omitted in the code snippet above. We just show it here for illustration purposes.
join vs query — when to use which?
Now with these two query strategies, you'll wonder: When to use which?
Because of the lateral, aggregated JOINs that Prisma ORM uses on PostgreSQL and the correlated subqueries on MySQL, the join strategy is likely to be more efficient in the majority of cases (a later section will have more details on this). Database engines are very powerful and great at optimizing query plans. This new relation load strategy pays tribute to that.
However, there may be cases where you may still want to use the query strategy to perform one query per table and merge data at the application-level. Depending on the dataset and the indexes that are configured in the schema, sending multiple queries could be more performant. Profiling and benchmarking your queries will be crucial to identify these situations.
Another consideration could be the database load that's incurred by a complex join query. If, for some reason, resources on the database server are scarce, you may want to move the heavy compute that's required by a complex join query with filters and pagination to your application servers which may be easier to scale.
TLDR:
- The new
joinstrategy will be more efficient in most scenarios. - There may be edge cases where
querycould be more performant depending on the characteristics of the dataset and query. We recommend that you profile your database queries to identify these scenarios. - Use
queryif you want to save resources on the database server and do heavy-lifting of merging and transforming data in the application server which might be easier to scale.
Understanding relations in SQL databases
Now that we learned about Prisma ORM's JOIN strategies, let's review how relation queries generally work in SQL databases.
Flat vs nested data structures for relations
SQL databases store data in flat (i.e. normalized) ways. Relations between entities are represented via foreign keys that specify references across tables.
On the other hand, application developers are typically used to working with nested data, i.e. objects that can nest other objects arbitrarily deep.
This is a huge difference, not only in the way how data is physically laid out on disk and in memory, but also when it comes to the mental model and reasoning about the data.
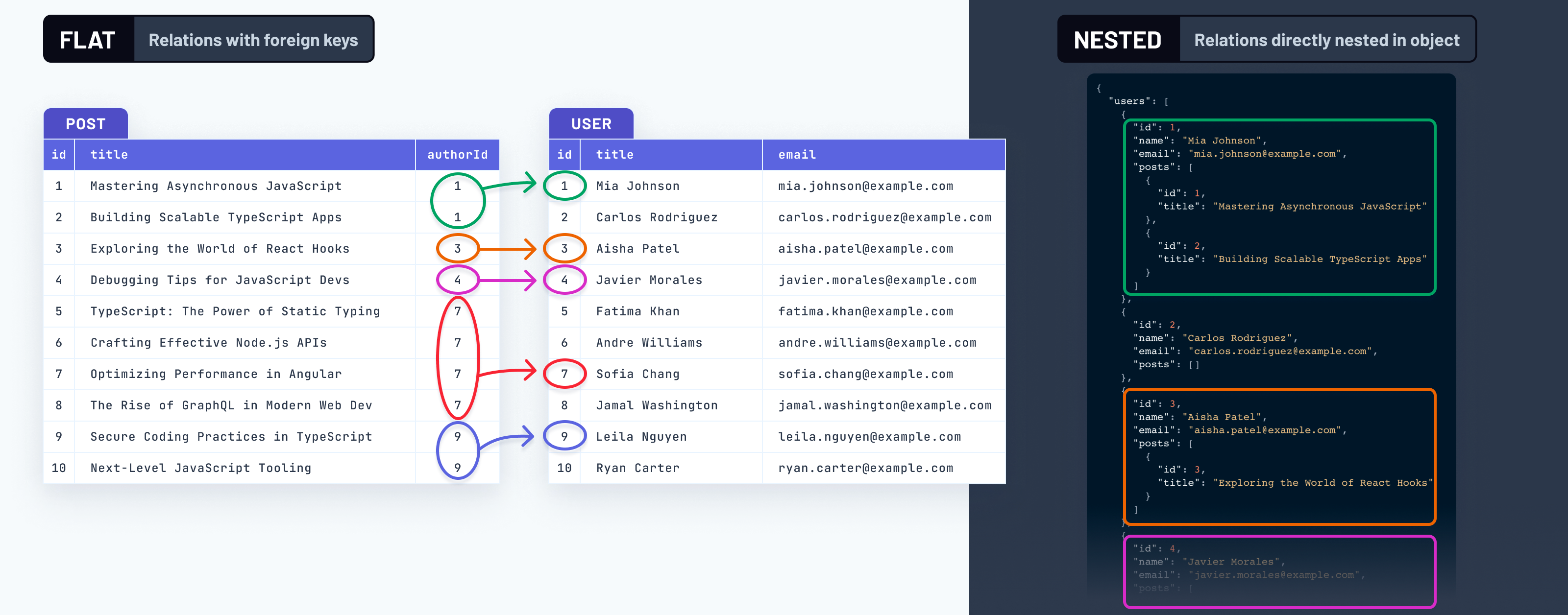
Relational data needs to be "merged" for application developers
Since related data is stored physically separately in the database, it needs to be merged somewhere to become the nested structure an application developer is familiar with. This merge is also called "join".
There are two places where this join can happen:
- On the database-level: A single SQL query is sent to the database. The query uses the
JOINkeyword or a correlated subquery to let the database perform the join across multiple tables and returns the nested structures. - On the application-level: Multiple queries are sent to the database. Each query only accesses a single table and the query results are then merged in-memory in the application layer. This used to be the only query strategy that Prisma Client supported before
v5.9.0.
Which approach is more desirable depends on the database that's used, the size and characteristics of the dataset, and the complexity of the query. Read on to learn when it's recommended to use which strategy.
What's happening under the hood?
Prisma ORM implements the new join relation load strategy using LATERAL joins and DB-level JSON aggregation (e.g. via json_agg) in PostgreSQL and correlated subqueries on MySQL.
In the following sections, we'll investigate why the LATERAL joins and DB-level JSON aggregation approach on PostgreSQL is more efficient than plain, traditional JOINs.
Preventing redundancy in query results with JSON aggregation
When using database-level JOINs, there are several options for constructing a SQL query. Let's consider the SQL table definition for the Prisma schema from above:
-- CreateTable
CREATE TABLE "User" (
"id" SERIAL NOT NULL,
"name" TEXT,
CONSTRAINT "User_pkey" PRIMARY KEY ("id")
);
-- CreateTable
CREATE TABLE "Post" (
"id" SERIAL NOT NULL,
"title" TEXT NOT NULL,
"authorId" INTEGER,
CONSTRAINT "Post_pkey" PRIMARY KEY ("id")
);
-- AddForeignKey
ALTER TABLE "Post" ADD CONSTRAINT "Post_authorId_fkey" FOREIGN KEY ("authorId") REFERENCES "User"("id") ON DELETE SET NULL ON UPDATE CASCADE;To retrieve all users with their posts, you can use a simple LEFT JOIN query:
SELECT
u.id AS user_id,
u.name AS user_name,
p.id AS post_id,
p.title AS post_title
FROM
"user" u
LEFT JOIN
post p ON u.id = p.author_id
ORDER BY
u.id, p.id;This is what the result could look like with some sample data:
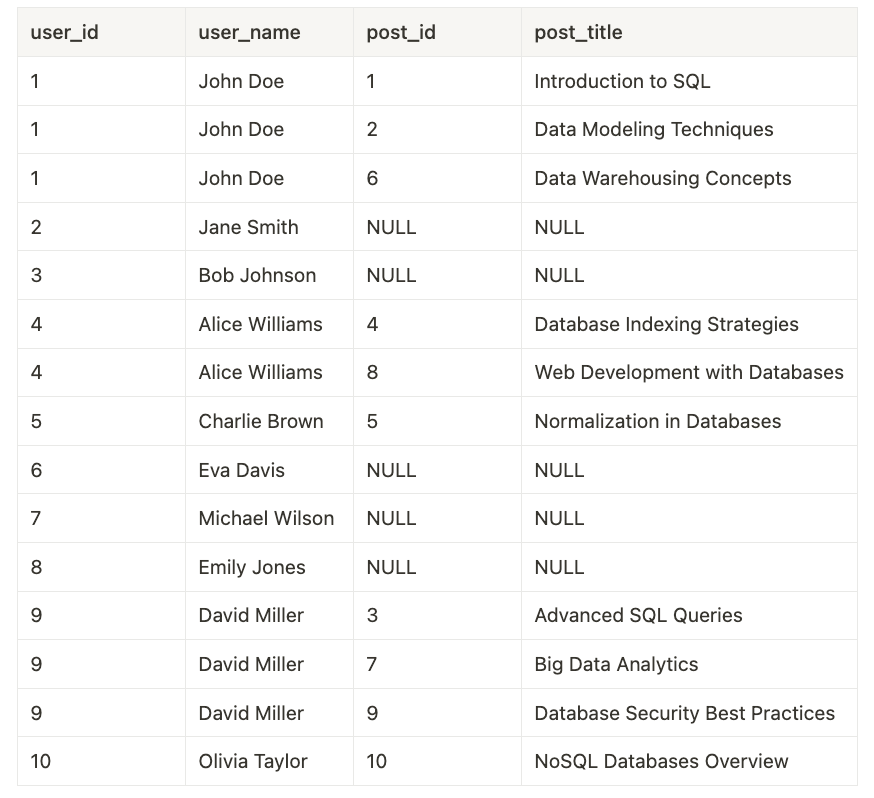
Notice the redundancy in the user_name column in this case. This redundancy is only going to get worse the more tables are being joined. For example, assume there's another Comment table, where each comment has a postId foreign key that points to a record in the Post table.
Here's a SQL query to represent that:
SELECT
u.id AS user_id,
u.name AS user_name,
p.id AS post_id,
p.title AS post_title,
c.id AS comment_id,
c.body AS comment_body
FROM
"user" u
LEFT JOIN
post p ON u.id = p.author_id
LEFT JOIN
comment c ON p.id = c.post_id
ORDER BY
u.id, p.id, c.id;Now, assume the first post had multiple comments:
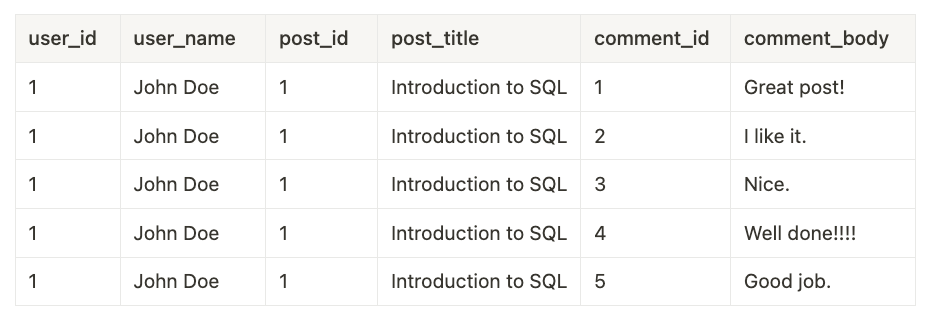
The size of the result set in this case grows exponentially with the number of tables that are being joined. Since this data goes over the wire from the database to the application server, this can become very expensive.
The join strategy implemented by Prisma with JSON aggregation on the database-level solves this problem.
Here is an example for PostgreSQL that uses json_agg and json_build_object to solve the redundancy problem and return the posts per user in JSON format:
SELECT
u.id AS user_id,
u.name AS user_name,
jsonb_agg(
jsonb_build_object(
'post_id', p.id,
'post_title', p.title
)
) AS posts
FROM
"user" u
LEFT JOIN
post p ON u.id = p.author_id
GROUP BY
u.id, u.name
ORDER BY
u.id;The result set this time doesn't contain redundant data. Additionally, the data structure conveniently already has the shape that's returned by Prisma Client which saves the extra work of transforming results in the query engine:

Lateral JOINs for more efficient queries with pagination and filters
Relation queries (like most other ones) almost never fetch the entire data from a table, but come with additional result set constraints like filters and pagination. Specifically pagination can become very complex with traditional JOINs, let's look at another example.
Consider this Prisma Client query that fetches 10 users and 5 posts per user:
await prisma.user.findMany({
take: 10,
include: {
posts: {
take: 5,
},
},
});When writing this in raw SQL, you might be tempted to use a LIMIT clause inside the sub-query, e.g.:
SELECT "user".id,
name,
title
FROM ("user"
LEFT JOIN
(SELECT *
FROM post
LIMIT 5) AS p ON (p.author_id = "user".id))
LIMIT 10;However, this won't work because the inner SELECT doesn't actually return five posts per user — instead it returns two posts in total which is of course not at all the desired outcome.
Using a traditional JOIN, this could be resolved by using the row_number() function to assign incrementing integers to the records in the result set with which the computation of the pagination could be performed manually.
This approach becomes very complex very fast though and thus isn't ideal for building paginated relation queries.
SELECT "user".id,
name,
title,
rn
FROM ("user"
LEFT JOIN
(SELECT *,
row_number() OVER (PARTITION BY author_id) AS rn
FROM post) AS p ON (p.author_id = "user".id))
WHERE p.rn >= 1
AND p.rn <= 5
OR p.rn IS NULL
LIMIT 10;Maintaining, scaling and debugging these kinds of SQL queries is daunting and can consume hours of development time.
Thankfully, newer database versions solve this with a new kind of query: the lateral JOIN.
The above query can be simplified by using the LATERAL keyword:
SELECT "user".id,
name,
title
FROM ("user"
LEFT JOIN LATERAL
(SELECT *
FROM post
WHERE post.author_id = "user".id
LIMIT 5) AS p ON TRUE)
LIMIT 10;This not only makes the query more readable, but the database engine also likely is more capable of optimizing the query because it can understand more about the intent of the query.
Conclusion
Let's review the different options for joining data from relation queries with Prisma.
In the past, Prisma only supported the application-level join strategy which sends multiple queries to the database and does all the work of merging and transforming it into the expected JavaScript object structures inside of the query engine:
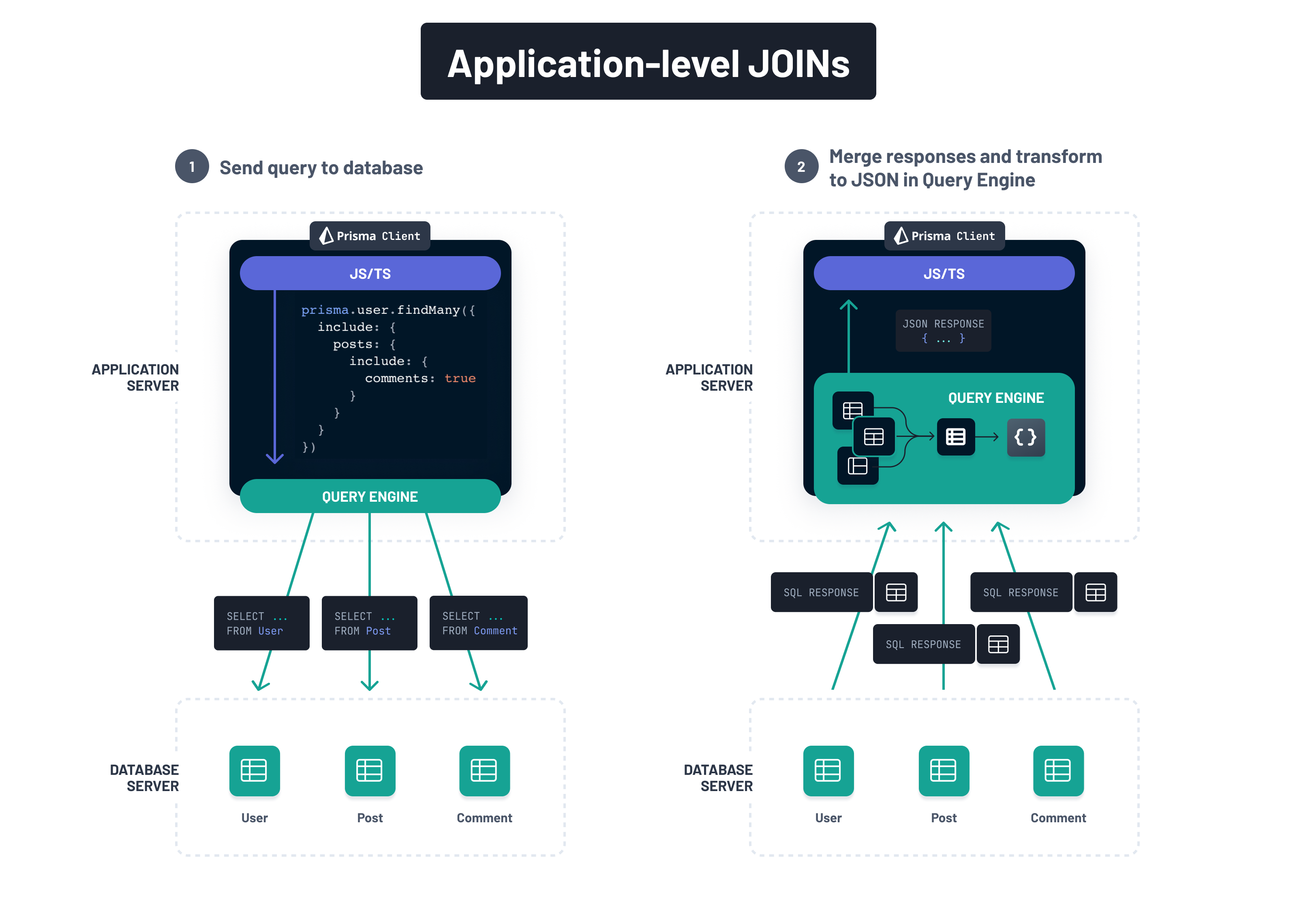
Using plain, traditional JOINs, the merging of the data would be delegated to the database. However, as explained above, there are problems with data redundancy (the result sets grow exponentially with the number of tables in the relation query) and the complexity of queries that contain filters and pagination:
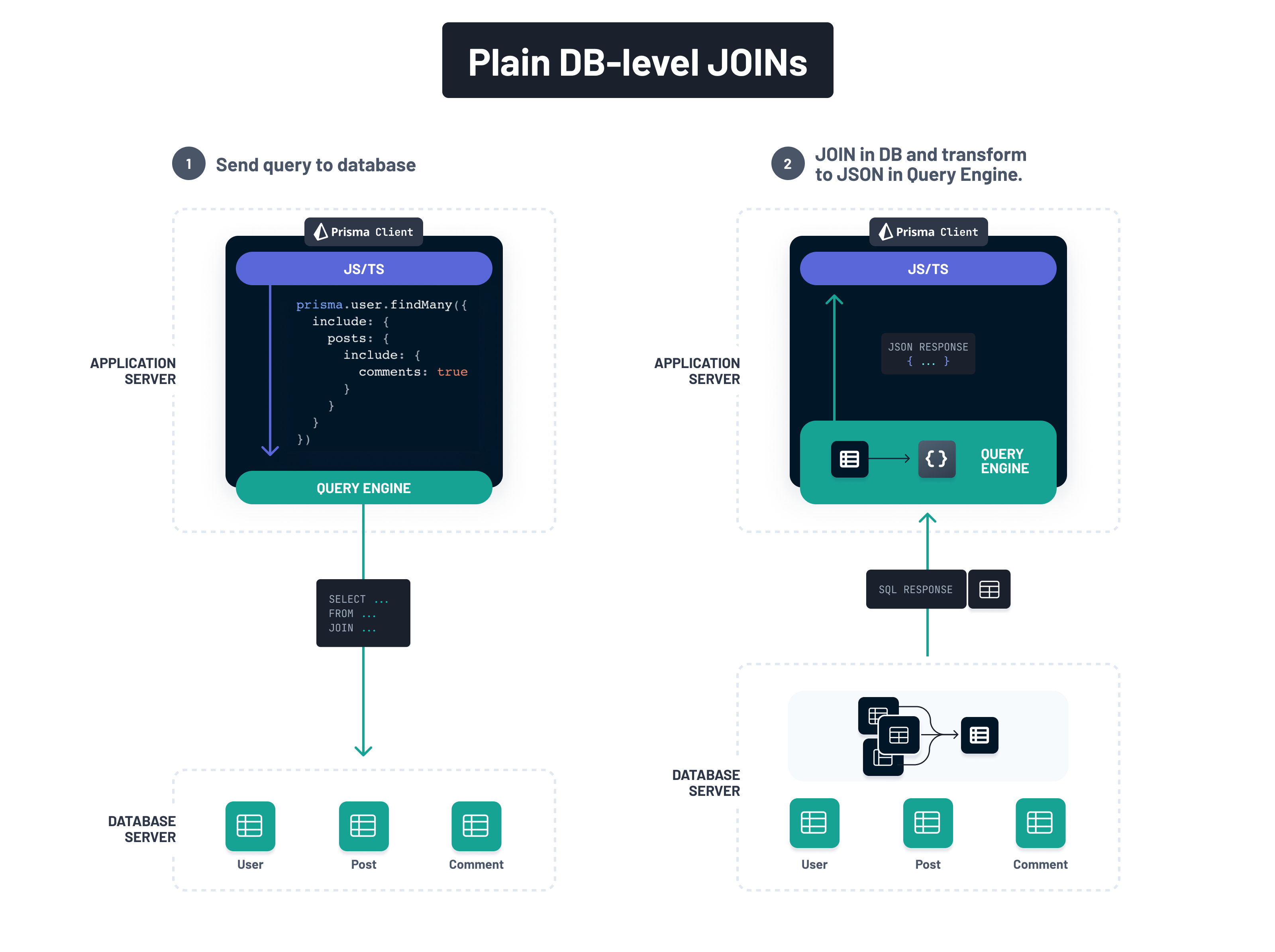
To work around these issues, Prisma ORM implements modern, lateral JOINs accompanied with JSON aggregation on the database-level. That way, all the heavy lifting that's needed to resolve the query and bring the data into the expected JavaScript object structures is done on the database-level:

Try it out and share your feedback
We'd love for you to try out to the new loading strategy for relation queries. Let us know what you think and share your feedback with us!