Top 5 Myths about Prisma ORM

Discover the truth behind five common misconceptions about Prisma ORM. In this article, we debunk the myths, explore their origins, and have a little fun separating fact from fiction.
- Myth 1: Prisma ORM is slow
- Myth 2: You can't use low-level DB features
- Myth 3: Prisma ORM uses GraphQL under the hood
- Myth 4: Prisma Client must live in
node_modules - Myth 5: Prisma doesn't work well with Serverless/Edge
- Help us make Prisma ORM the best DB library 💚
Myth 1: Prisma ORM is slow
When we initially released Prisma ORM for production in 2021, we followed the "Make it work, make it right, make it fast" approach. This means the initial version of Prisma ORM hadn't been particularly optimized for speed.
However, since then we have invested heavily into performance and have released performance improvements in almost every release.
We also created open-source ORM benchmarks comparing the three most popular ORMs in the TypeScript ecosystem and found that Prisma ORM's performance is similar to the others, sometimes even faster.
Major performance improvements in almost every release
Prisma ORM has been following a steady and reliable release cadence in cycles of three weeks. If you check out the release page of the prisma/prisma repo, you'll notice that almost every release came with some kind of performance improvements — be it an optimization of a particular SQL query (as seen in, 5.11.0, 5.9.0, 5.7.0, 5.4.0, 5.2.0, 5.1.0, …), introducing new batch queries like createManyAndReturn (in 5.14.0), speeding up cold starts by 9x (in 5.0.0) or introducing support for native JS-based drivers (in 5.4.0).
We are also working on rewriting the Rust-based Query Engine from Rust to TypeScript to save some overhead in serialization between language boundaries and are expecting notable performance improvements from this change as well.
Prisma ORM lets you choose the best JOIN strategy
Another huge win for developers using Prisma ORM was the ability to pick the best JOIN strategy for their relation queries.
In principle, there are two different approaches when you need to query data from multiple tables that are related via foreign keys:
Database-level: Using the JOIN keyword in a single query
With this approach, you send a single query to the database using the SQL JOIN keyword and let the data be joined by the database directly:
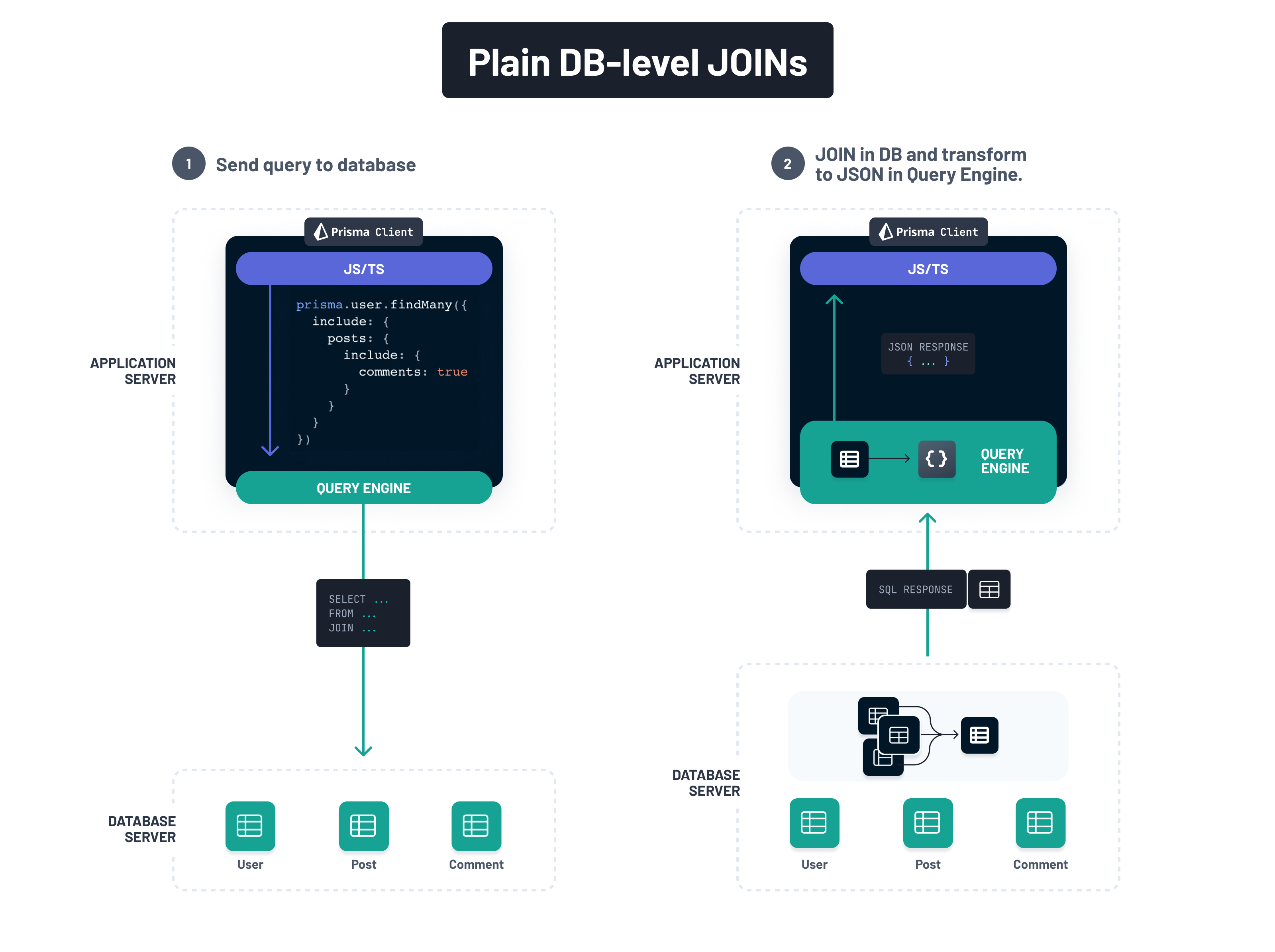
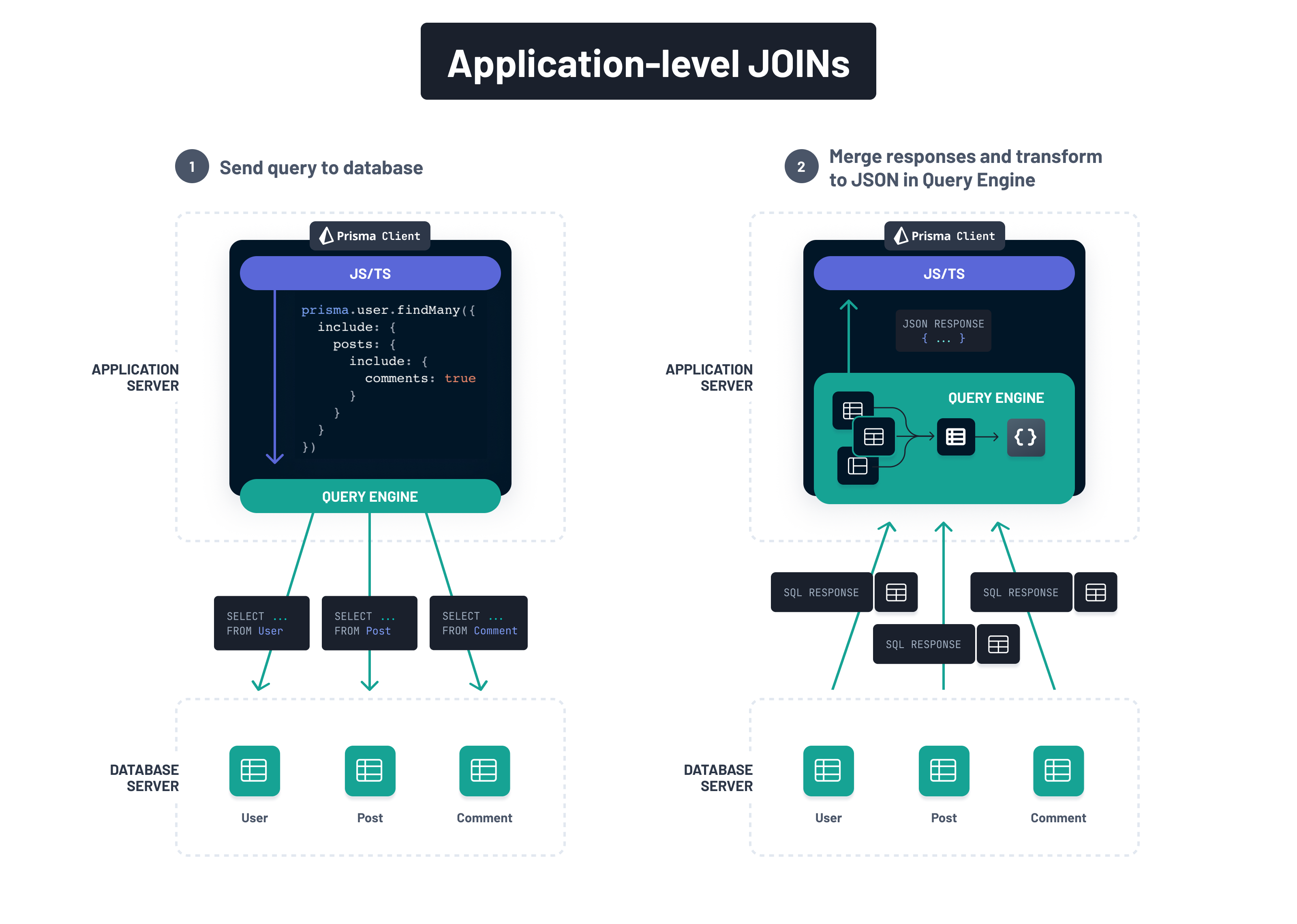
Application-level: Send multiple queries and join in application
When joining on the application-level, you send multiple queries to individual tables to the database and join the data yourself in your application:
When to use which?
Depending on your use case, dataset, schema, and several other factors, one strategy may be more performant than the other. The application-level joining method is also called join decomposition and often used in high-performance environments:
Many high-performance web sites use join decomposition. You can decompose a join by running multiple single-table queries instead of a multitable join, and then performing the join in the application.
High Performance MySQL, 2nd Edition | O'Reilly
Up until Prisma ORM 5.7.0, Prisma ORM would always use the application-level JOIN strategy. However, with the 5.7.0 release, we now allow you to pick the best JOIN strategy for your use case, ensuring you can always get the best performance for your queries.
ORM benchmarks: No major performance differences
After all these improvements, we wanted to know where Prisma ORM stands in terms of performance in comparison to other ORM libraries. So, we created transparent benchmarks comparing the query performance of TypeORM, Drizzle ORM and Prisma ORM.
The benchmark repo is open-source and we're inviting everyone to reproduce the results and share them with us.
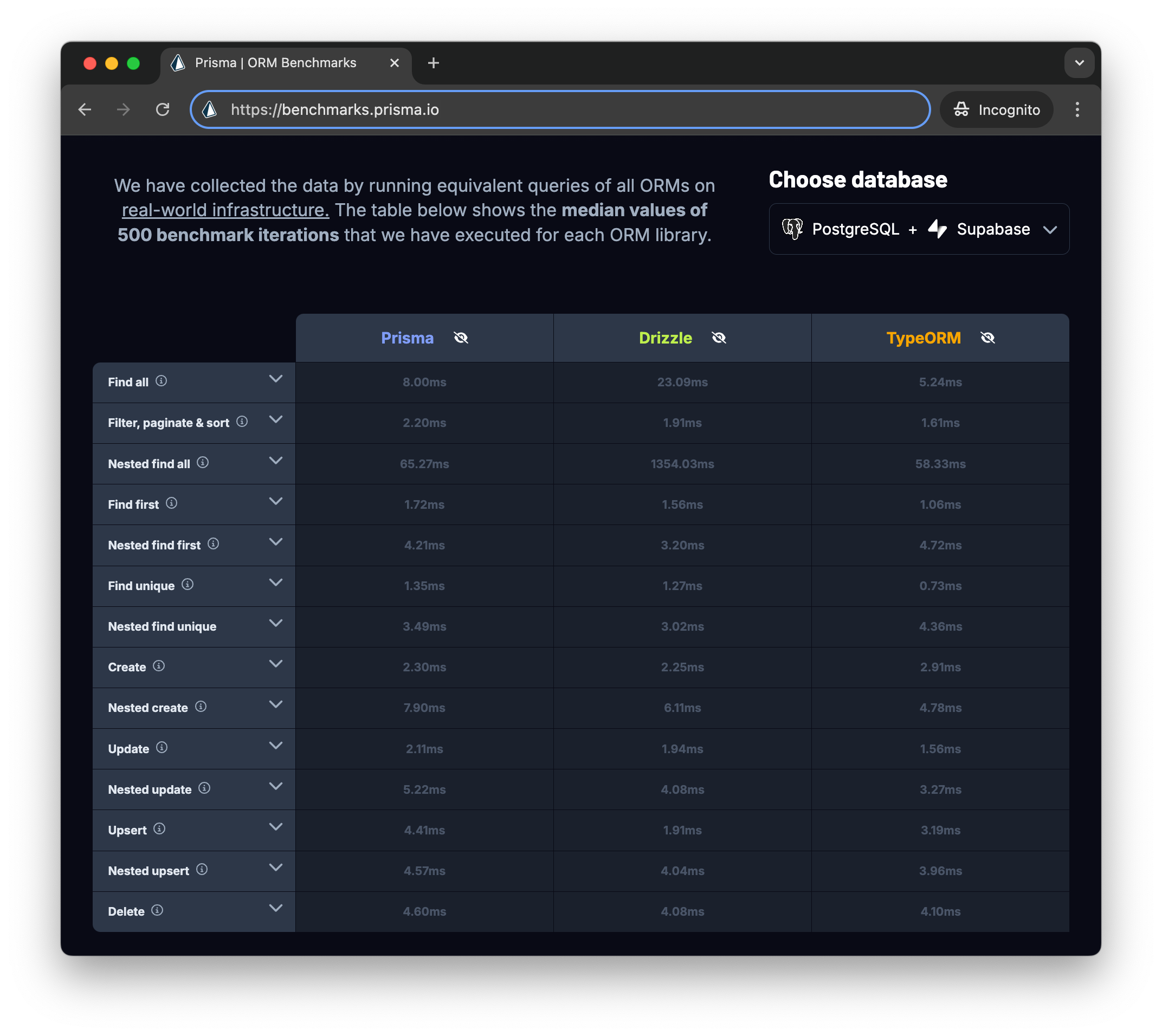
So, what did the benchmarks show?
TLDR: Based on the data we've collected, it's not possible to conclude that one ORM always performs better than the other. Instead, it depends on the respective query, dataset, schema, and the infrastructure on which the query is executed..
You can read more about the setup, methodology and results of the benchmarks here: Performance Benchmarks: Comparing Query Latency across TypeScript ORMs & Databases.
Make your queries faster with Prisma Optimize
One major insight from running the benchmarks was that it's possible to write fast and slow queries, regardless which tools you use. Meaning that in the end, a lot of the burden to ensure database queries are fast is actually on the developer themself.
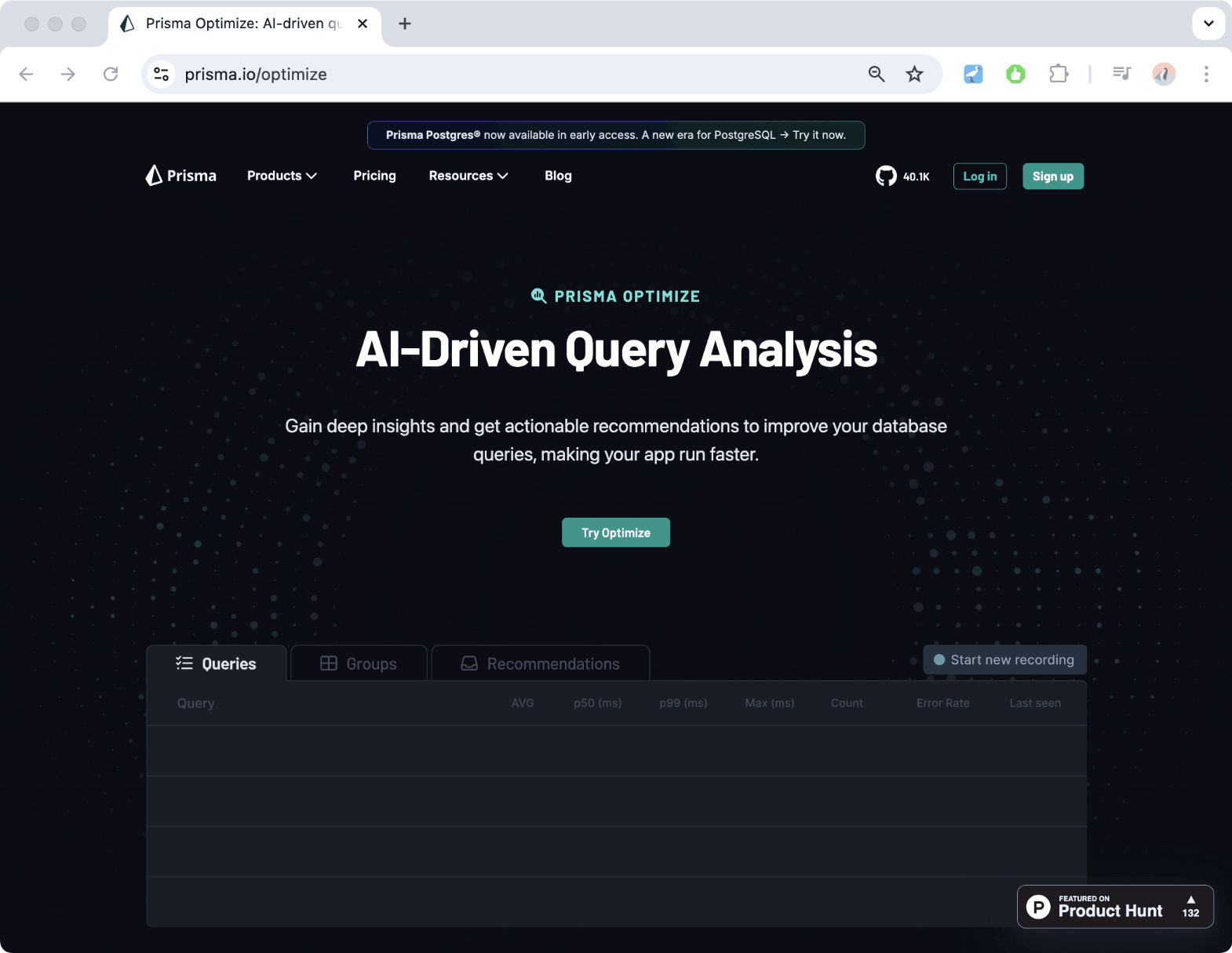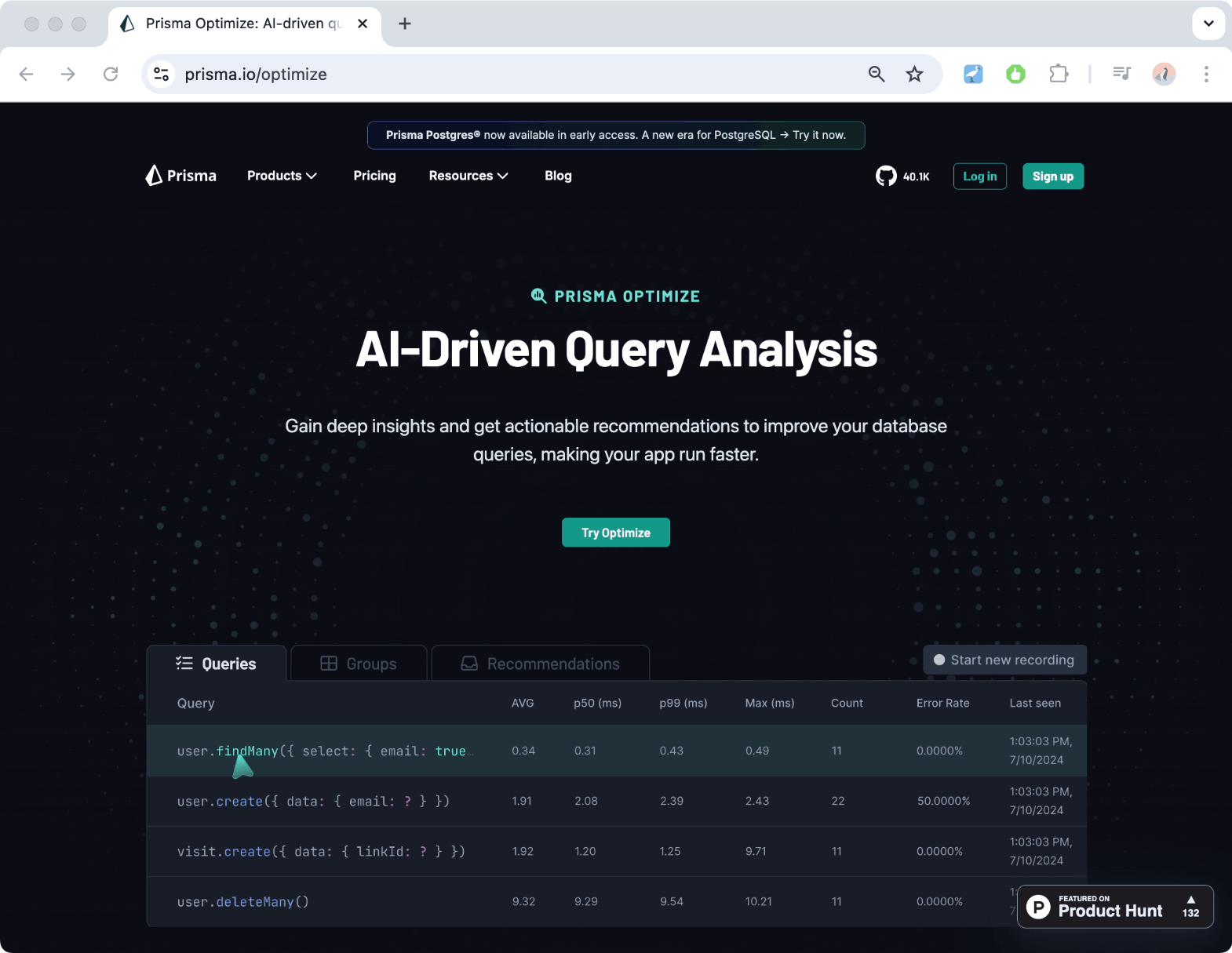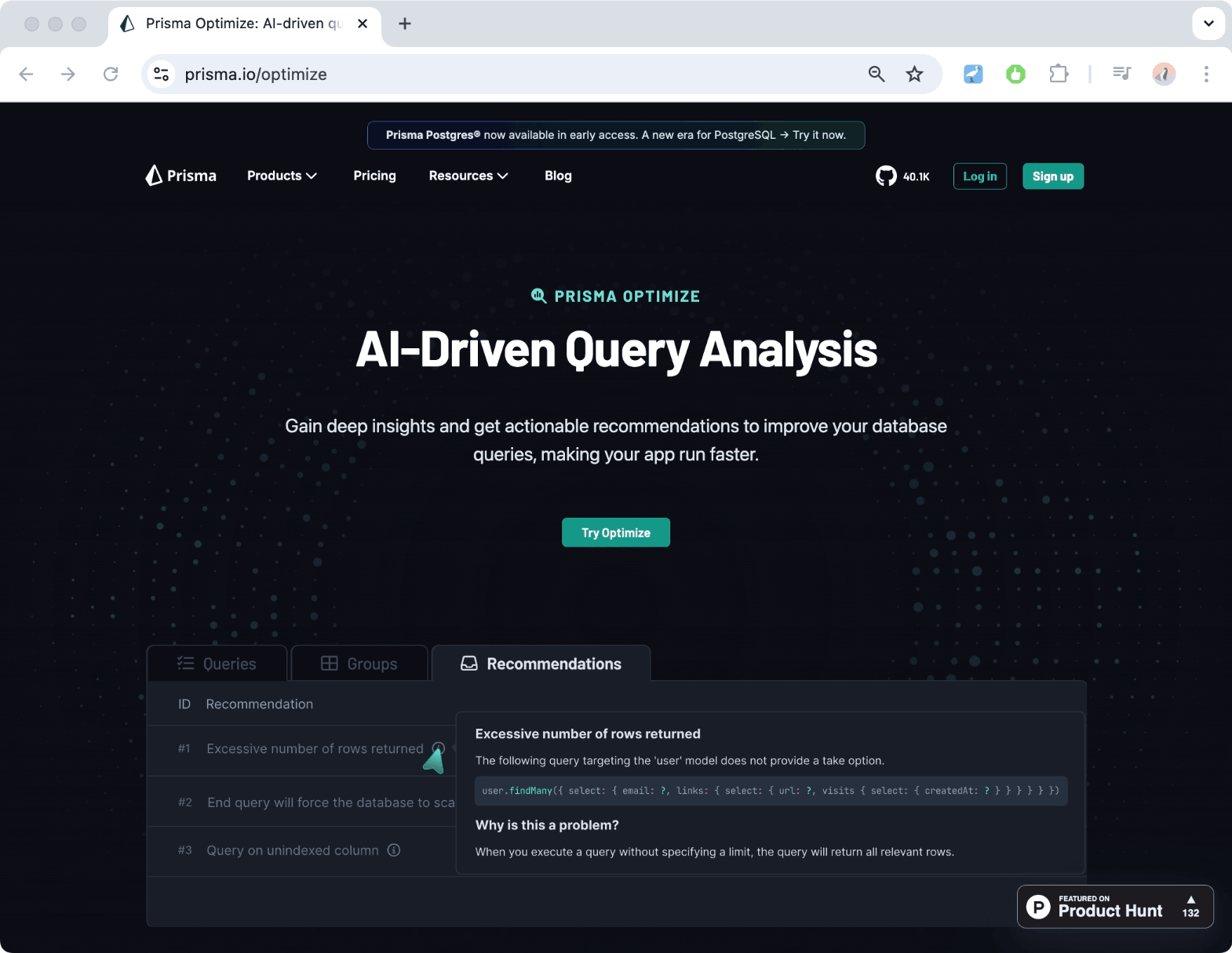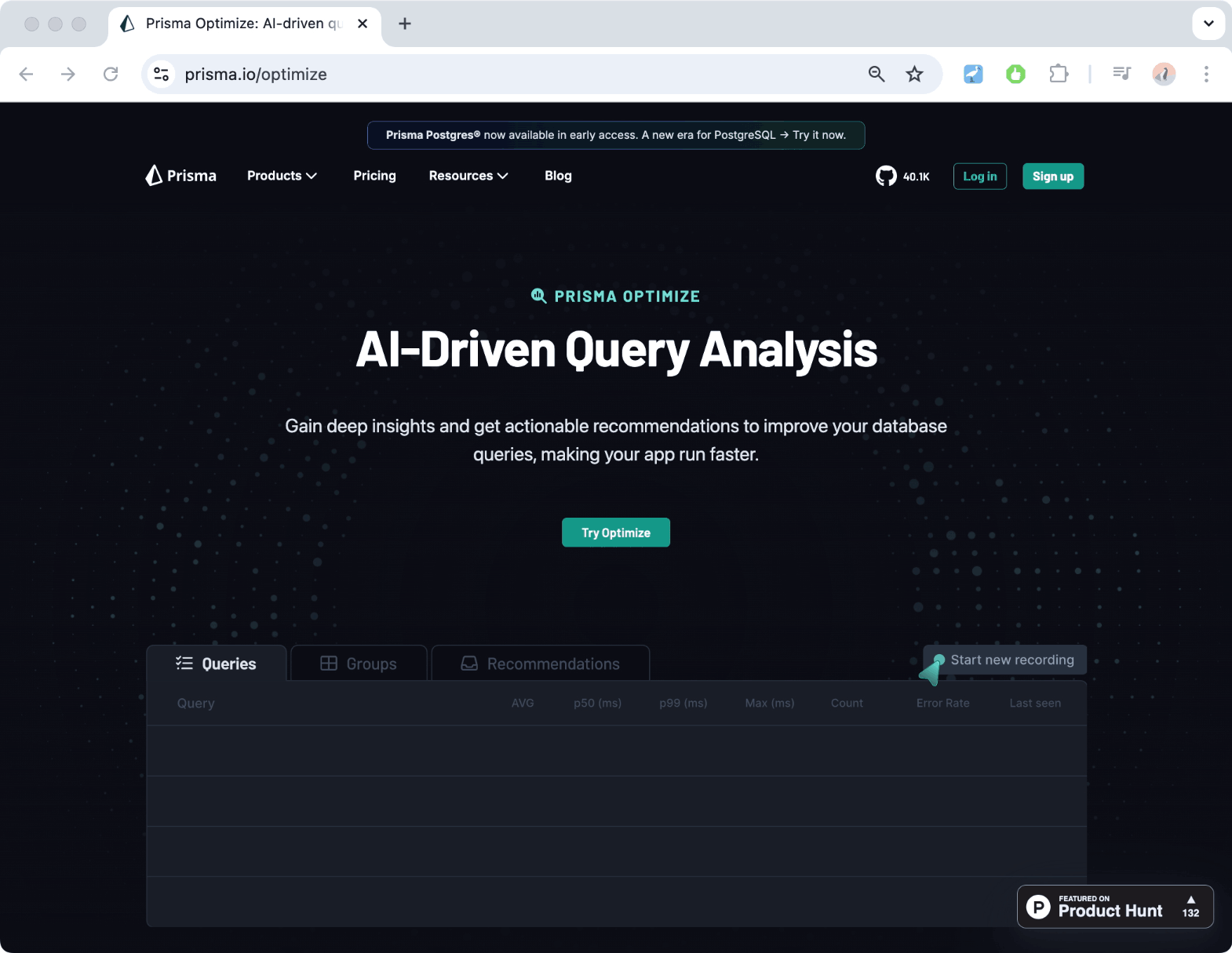
To ensure developers using Prisma ORM are making their queries as fast as possible, we recently launched Prisma Optimize — a tool that analyzes the queries you send to your database with Prisma ORM and gives you insights and recommendations for how to improve them.
Myth 2: You can't use low-level DB features
Prisma ORM—by nature of being an ORM—provides a higher-level abstraction over SQL in order to improve productivity, confidence and overall developer experience when working with databases.
This higher-level abstraction manifests in the human-readable Prisma schema (to describe the structure of your database) and the intuitive Prisma Client API (for querying the database).
However, given that an abstraction also sometimes make it impossible to access functionality of the underlying technology (in the case of Prisma ORM: a database), a proper escape hatch is needed to drop down to a lower level of abstraction.
So, in order to not sacrifice important features that may be needed in more advanced scenarios or edge cases, Prisma ORM provides convenient fallbacks for developers to access the underlying functionality of the database.
Customized migrations let developers use any SQL feature
While it's not possible to represent all the features a database may have in the Prisma schema, you can still make use of these by customizing the migration files that are generated by Prisma Migrate.
To do so, you can simply use the --create-only flag whenever you create a new migration and make edits to it before it's applied against the database.

Using customized migrations, you can freely manipulate your database schema while ensuring that all changes are executed by Prisma Migrate and tracked in its migration history.
Write type-safe SQL in Prisma ORM
When it comes to queries, there are two main ways how developers can drop down to raw SQL and write queries that can't be expressed using the higher-level query API.
TypedSQL: Making raw SQL type-safe
Prisma ORM now gives you the best of both worlds: A convenient high-level abstraction for the majority of queries and a flexible, type-safe escape hatch for raw SQL.
Consider this example of a raw SQL query you may need to write in your application:
-- prisma/sql/conversionByVariant.sql
SELECT "variant", CAST("checked_out" AS FLOAT) / CAST("opened" AS FLOAT) AS "conversion"
FROM (
SELECT
"variant",
COUNT(*) FILTER (WHERE "type"='PageOpened') AS "opened",
COUNT(*) FILTER (WHERE "type"='CheckedOut') AS "checked_out"
FROM "TrackingEvent"
GROUP BY "variant"
) AS "counts"
ORDER BY "conversion" DESCAfter a generation step, you'll be able to use the conversionByVariant query via the new $queryRawTyped method in Prisma Client:
import { PrismaClient } from '@prisma/client'
import { conversionByVariant } from '@prisma/client/sql'
// `result` is fully typed!
const result = await prisma.$queryRawTyped(conversionByVariant())Learn more about this on our blog: Announcing TypedSQL: Make your raw SQL queries type-safe with Prisma ORM
Use the Kysely SQL query building extensions
Another alternative is to use the Prisma Client extensions for Kysely which lets developers build SQL queries using its TypeScript API. For example, using the Kysely extension you can write SQL queries with Prisma as follows:
const query = prisma.$kysely
.selectFrom("User")
.selectAll()
.where("id", "=", id);
// Thanks to kysely's magic, everything is type-safe!
const result = await query.execute();This enables you to write advanced SQL queries without leaving TypeScript and Prisma ORM.
Fun fact: Kysely's core maintainer Igal recently joined our team at Prisma 😄
Myth 3: Prisma ORM uses GraphQL under the hood
Depending on how long you've been around in the Prisma community, this may surprise you: Prisma used to be a GraphQL Backend-as-a-Service provider called Graphcool:
In 2018, Graphcool rebranded to Prisma and climbed down the "abstraction ladder" from the API layer to the database.
The first version of Prisma (before it became an ORM), was a CRUD GraphQL layer between your API server and database:

At this point, the main value that Prisma 1 provided was the convenient data modeling, migrations querying which were all done via GraphQL.
In order to simplify usage of Prisma and avoid requiring users to set up and maintain an entirely separate server, we rewrote Prisma's GraphQL engine in Rust, making it available as a binary downloadable via npm install:

The Query Engine was running a GraphQL server as a side-car process on the application server. Developers were interacting with it using Prisma Client and writing queries TypeScript. This was the initial architecture of Prisma ORM.
Since then, we have made countless optimizations to the architecture. Most notably, we introduced N-API for the communication between Rust and TypeScript, replaced GraphQL with a custom, JSON-based wire protocol, enabled usage of JS-native database drivers and a lot more!
Today, there's no residue of GraphQL in Prisma ORM any more — and we're not stopping here either, we keep improving the architecture of Prisma ORM. Our next step is to move the Query Engine that does the heavy-lifting of generating SQL from Rust to TypeScript and make Prisma ORM even more efficient.
Myth 4: Prisma Client must live in node_modules
A common misconception developers have about Prisma ORM is that the generated Prisma Client library must live in node_modules.
However, node_modules is just the default location to provide a familiar developer experience and enable simple imports:
// When Prisma Client is in `node_modules`:
import { PrismaClient } from "@prisma/client";That location can be easily customized by providing a custom output path on the generator block:
generator client {
provider = "prisma-client-js"
output = "../src/generated/client"
}In that case, you need to adjust the import statements and import Prisma Client from your file system. Considering the example above, the import would now look like this:
// When Prisma Client is in `./generated/client`:
import { PrismaClient } from "./generated/client";This can be really useful when you are working in a monorepo or other special environment where generating Prisma Client into node_modules may cause problems.
Myth 5: Prisma doesn't work well with Serverless/Edge
When Prisma ORM was designed, Serverless and Edge deployments still were early and emerging technologies. Since then, they have become a popular deployment model that a lot of development teams rely on.
The initial architecture of Prisma ORM, with the Query Engine binary and the internal GraphQL server, wasn't optimized for Serverless environments and there were numerous problems:
- Slow cold starts due to the GraphQL-based wire protocol.
- No ability to use Serverless Drivers of modern DB providers (like Neon and PlanetScale); this entirely prevented usage of Prisma Client at the Edge.
- Large bundle size due to Query Engine binary.
- Added complexity by needing to declare
binaryTargetsif the local machine differed from the target machine.
We have recognized all of these problems and, over time, have implemented solutions and drastically improved the DX of Prisma ORM in Serverless environments:
- The cold starts aren't a problem any more since we removed GraphQL from the Query Engine internals and sped up cold starts by 9x.
- Serverless and other JS-native database drivers (like
pg) can now be used with Prisma ORM thanks to driver adapters. - We have reduced the bundle size of Prisma ORM to less than 1MB, making it possible to use it in the free plans of major Edge function providers (like Cloudflare, who have a 3MB limit for their free plans).
- … and we are working on further improvements: The move from Rust to TypeScript will remove the need to declare
binaryTargetsand overall make the deployment of Prisma ORM a lot more smooth than it ever was.
Help us make Prisma ORM the best DB library 💚
At Prisma, we strongly value the feedback we receive from our community! While some of the misconceptions floating around about Prisma ORM may have been true in the past, we heard our users and have been hard at work to improve the situations around them.
If you're curious to learn more about our approach to open-source governance, check out the Prisma ORM Manifesto.
We are going to continue our efforts to make Prisma ORM the most performant database library with the best possible DX in the TypeScript ecosystem. Let us know via GitHub, Discord or X what other improvements you like to see 🙌
If you're excited about Prisma ORM, you can help us clarify these misconceptions by sharing this post whenever you see some of them pop up in the developer community. Also, if there are any more myths you'd like us to bust, tell us!